
Blog
This article is part of an ongoing series taking a deep look at Amazon’s Well-Architected Framework, which is an incredible collection of best practices for cloud-native organizations. This month, we’re digging into the Reliability Pillar.
Background Information
It is a common misconception that reliable systems never encounter infrastructure or service disruptions, misconfigurations, or network issues. The reality is that reliable systems will encounter all of these issues. To achieve reliability, a system must be intentionally architected to quickly recover from failure. Architecting self-healing, resilient systems requires a deep understanding of the priorities of that system, including the potentially differing availability requirements of its component parts. In short: architecting for reliability can be quite a challenge.
Thankfully, the AWS Well-Architected Framework provides best practices and guidelines that can help demystify reliability. Amazon’s Reliability Pillar Whitepaper states:
Achieving reliability can be challenging in traditional on-premises environments due to single points of failure, lack of automation, and lack of elasticity. By adopting the practices in this paper you will build architectures that have strong foundations, consistent change management, and proven failure recovery processes.
While Amazon is correct that achieving reliability is difficult in on-prem environments, it can be equally challenging in the cloud without a solid foundation of best practices.
Understanding Availability
Before we dive into the best practices from AWS, we first need to understand what we mean by “availability.” In Amazon’s view, availability is defined as: “the percentage of time that an application is operating normally.” Generally speaking, availability is calculated over a specific time period, using a simple formula:
Availability = Normal Operation Time / Total Time
We’ve all heard availability described in terms of a number of “nines,” but I find it helpful to translate those into more practical, easily understood measures:
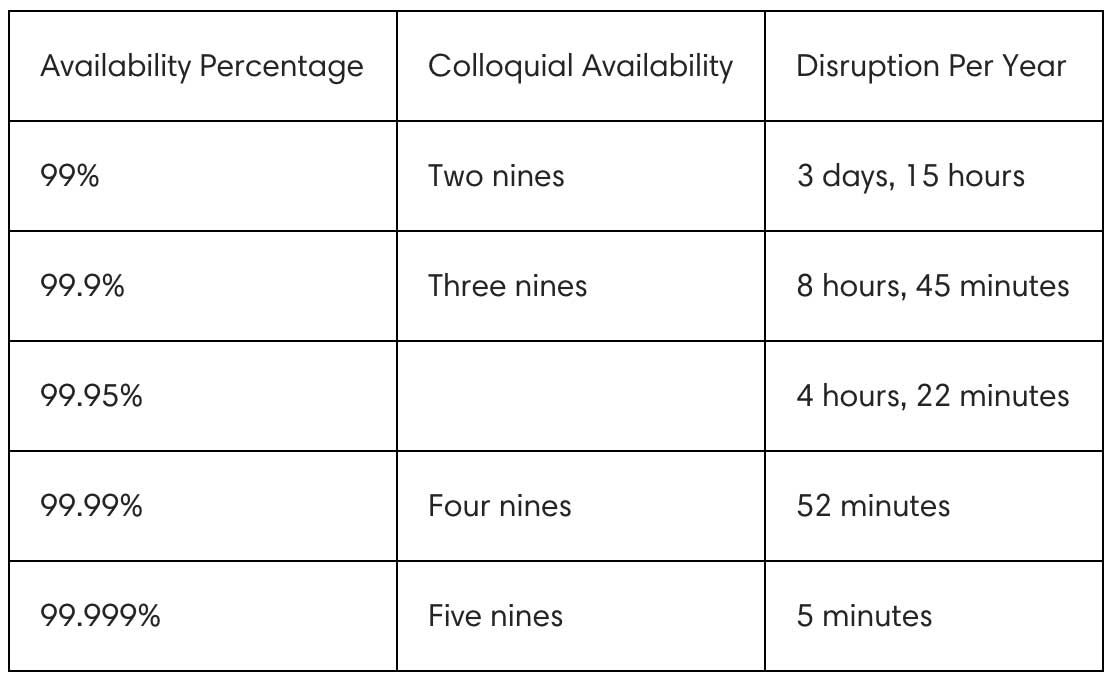
It is important to note that not every application and system requires the same level of availability to be considered reliable. Application and system requirements and priorities will vary! For example, an ETL system or batch processing system may find two nines of availability sufficient to qualify as reliable, while critical financial systems may have much higher demands.
Calculating Total System Availability
When calculating availability, you also need to consider any downstream systems that may constitute a “hard” dependency, where a disruption to the downstream service directly translates into a disruption on the upstream system. Adding hard dependencies downstream directly impacts the theoretical availability of your application.
Similarly, availability calculations should take into account the use of redundant systems like availability zones (AZs). Taking advantage of AZs can have a measured positive impact on the maximum theoretical availability of your applications and services.
For more detail on calculating availability, refer to the AWS Well-Architected Pillar Whitepaper, or this detailed review of calculating total system availability.
Availability isn’t Free
Overestimating the true availability requirements of a system can have disastrous consequences. As availability requirements increase, so does cost to provide service, with additional redundant systems becoming necessary and the need to limit hard dependencies. In addition, costs for software development can quickly balloon as you drive for higher levels of availability. Your teams will also need to move more slowly when dealing with extremely high levels of availability, which can negatively impact your ability to innovate. Therefore, it’s critical that you endeavour to accurately identify the true availability requirements of a system.
Networking and Availability
Architecting reliable systems in the cloud requires a diligent approach to networking. There are a myriad of concerns to keep in mind, including:
- Network topology
- Future growth
- Networking across Availability Zones and Regions
- Resilience to failures and misconfiguration
- Traffic patterns
- DDoS mitigation
- Private connectivity
AWS provides an extensive suite of tools and services to help you design highly available networks, including AWS VPC, AWS Direct Connect, Amazon Route 53, Amazon Elastic Load Balancing, AWS Shield, and more. That said, it’s important to be armed with some best practices to consider when designing your network:
- Always use private address ranges for your VPC blocks, and select large, non-overlapping address spaces to plan for future growth. The 10.x.x.x base address space has over 16,000,000 IP addresses, and the largest VPC allocation accommodates over 65,000 IP addresses. AWS advises that you err on the side of “too much” rather than “too little.”
- Amazon VPC provides many network connectivity options, including options that leverage either the internet or an AWS Direct Connect connection. In addition, VPC Peering gives you the ability to connect VPCs within and across regions. Finally, there are a host of VPN options that provide private connectivity to consider. AWS provides an excellent whitepaper entitled Amazon Virtual Private Cloud Connectivity Options to help guide your networking decisions.
- Consider security and protection when designing your network topology, making sure to leverage existing standards for protection within a private address space. Using subnets can help provide a barrier between your applications and the internet. In addition, consider deflecting DoS attacks, such as SYN floods, using AWS Shield, AWS Web Application Firewall (WAF), and AWS Shield Advanced.
Recovery Oriented Computing
Creating a workload that is inherently resilient and reliable requires a specific mindset. Researchers have coined the term “Recovery Oriented Computing,” or ROC, to define a systematic approach to improving recovery in the case of failure.
The main characteristics that ROC identifies to enhance recovery are:
- Isolation and redundancy
- System wide ability to roll back changes
- Ability to monitor and determine health
- Ability to provide diagnostics
- Automated recovery
- Modular design
- Ability to restart
ROC embraces the fact that failures occur in every system, and that those failures are broad in their type and scope, from hardware and software failures, to lapses in communication or operations. ROC prioritizes rapid detection of failure and automating well-tested recovery paths.
ROC avoids creating many special cases, instead choosing to map many different failure types to a small, well-tested set of recovery paths. An oft repeated mistake when designing reliable systems is to rely on recovery paths that are rarely tested.
Our experience has shown that the only error recovery that works is the path you test frequently. This is why having a small number of recovery paths is best.
AWS itself applies ROC principles when building AWS services, and through the rest of this blog post, we’ll be exploring ROC best practices.
High Availability Applications
In order to design and architect your application to meet your availability goals, you first need to quantify those needs. AWS recommends starting by asking a few simple questions:
- What problems are you trying to solve?
- What specific aspects of the application require specific levels of availability?
- What amount of cumulative downtime can this workload realistically accumulate in a year?
- In essence, what’s the real impact of the system being unavailable?
Armed with good answers to these questions, you can embark upon designing your system. AWS breaks this down into three parts:
- Understanding Availability Needs
- Application Design for Availability
- Operational Considerations for Availability
Understanding Availability Needs
Most applications aren’t monolithic systems with a single availability target. Generally speaking, you can break an application down into several components, each with different availability requirements. For example, an eCommerce application may set very high availability targets for accepting new orders, while having a lower availability target for processing and fulfilling those orders. By breaking your systems down into these component pieces, you can better understand your availability needs, and design your systems to meet those targets in a cost-effective way.
AWS Recommendation: Critically evaluate the unique aspects to your applications and where appropriate, differentiate the availability design goals to reflect the needs of your business.
Many organizations, including AWS, divide services into “data plane” and “control plane” classifications. The data plane is responsible for delivering service, often in real time, while the control plane is reserved for less critical configuration activities. In the AWS world, data plane operations include DynamoDB read/write operations, RDS connectivity, and EC2 instance connectivity. Example control plane operations include launching EC2 instances, S3 bucket creation, and RDS instance provisioning. Most organizations reserve the highest levels of availability for data plane services, and tolerate lower levels of availability for the control plane. By taking a similar approach with your own systems, you can identify the most critical components of your system, and focus your efforts there.
Application Design for Availability
AWS has extensive experience operating Amazon.com on top of AWS, and has engaged with thousands of customers to help them design their applications for availability. From their broad experience, AWS has identified five common practices to apply to improve availability:
- Fault Isolation Zones
- Redundant components
- Micro-service architecture
- Recovery Oriented Computing
- Distributed systems best practices
Let’s do a deep dive on each.
Fault Isolation Zones
As most applications are assembled from multiple components with varying availability along with service dependencies, you’ll need techniques to increase the availability of the total system beyond the availability of the individual components. AWS provides several different “Fault Isolation Zone” constructs to help you with this, the most notable of which are Availability Zones and Regions.
Availability Zones are an ideal choice for fault isolation when low latency is required, such as active/active configurations that require synchronous replication. Regions are more isolated from one another, but given their geographic separation, cross-region operations aren’t suitable for low latency use cases.
Redundant Components
Avoiding single points of failure in physical infrastructure is “a bedrock principle for service design in AWS.” By leveraging Fault Isolation Zones like AZs and Regions to deploy redundant components that operate in parallel, you can increase total system availability. Similarly, you should ensure that your systems are designed to tolerate failures within an AZ where possible, by deploying systems to multiple compute nodes, storage volumes, etc. Fault Isolation Zones, coupled with Redundant Components, represent AWS’ approach to the ROC concept of isolation and redundancy.
Micro-Service Architecture
Microservices are one of the hallmark architectural evolutions of the cloud era, and a well-known approach to the ROC characteristic of modular design. The biggest benefit of microservices is right there in their name – they’re small and simple! By dividing your application into simple, well-defined microservices, you can focus your attention and investment on microservices that have the greatest availability needs.
Microservices are a variant of Service-Oriented Architectures that push for creating the simplest, most focused set of functionality possible. Microservices are well defined and documented, and should publish their availability targets. This represents a sort of “contract” with calling applications, with significant benefits to both the application and the microservice itself. AWS calls out three key benefits to microservices:
- The service has a concise business problem to be served and a small team that owns the business problem. This allows for better organizational scaling.
- The team can deploy at any time as long as they meet their API and other “contract” requirements
- The team can use any technology stack they want to as long as they meet their API and other “contract” requirements.
That said, microservices don’t come without tradeoffs. By assembling an application out of microservices, you will be creating a distributed compute architecture. Debugging can be more challenging in such systems, low-latency is more difficult to achieve, and operational complexity is increased. Following the other best practices in the Well-Architected Framework and leveraging tools like AWS X-Ray for debugging can help mitigate these concerns.
Distributed Systems Best Practices
As you are applying the best practices introduced in the Well-Architected Framework to your workloads, you’ll quickly realize that you’re building distributed systems. Distributed systems are built out of loosely-coupled components deployed across fault isolation zones, interconnected by networks. It’s important to be armed with best practice patterns to ensure that your distributed systems elegantly recover from disruptions.
Throttling
When building microservices, measure and understand the capacity of your service to handle incoming requests. Once the capacity is understood, a defensive pattern of throttling requests can be implemented to ensure that the service remains responsive, even in periods of high load. By signaling that a request has been throttled, you enable the consumer of the service to elegantly retry their request later, or to fail over to a redundant copy of the component. The AWS API Gateway has built-in support for request throttling.
Retry with Exponential Fallback
On the consuming side of a web service, you should handle throttled requests using this pattern, where retry attempts are repeated after increasingly longer pauses. By “backing off” on retries, you ensure that you won’t overwhelm your web services with retries.
Fail Fast
A common anti-pattern in distributed systems is to queue up requests in the event of a disruption, and then to work through the queue when the system recovers. Whenever possible, you should prefer to fail fast, and return errors, rather than queueing up requests, which can significantly delay recovery.
Idempotency Tokens
Idempotency is a big word for “repeatable without side effects.” Wikipedia defines idempotency as:
Idempotence is the property of certain operations in mathematics and computer science that they can be applied multiple times without changing the result beyond the initial application.
In distributed systems, retries and timeouts are not uncommon, so idempotence is a particularly important feature to build into your microservices. One approach is to issue API requests with idempotency tokens, which is used on repeated requests. Your microservices can then use the token to determine if the work requested has already been completed, and if it has, simply return an identical success response.
Constant Work
Managing load is a difficult problem, particularly in distributed systems. By designing your services for “constant work,” you can distribute that load over time to improve resiliency. A common pattern is to occupy idle time with “filler work.”
Circuit Breaker
As we’ve discussed, hard dependencies can have a cascading impact on the availability of your services, so they must be taken on with care. One approach to avoiding hard dependencies is to implement a “circuit breaker” that controls the flow of requests to a downstream dependency. In this case, the downstream dependency is monitored in a loop, and if there is an availability issue with the service, then the circuit breaker is toggled, and the dependency is either ignored, with requests attempted later, or the data is replaced with locally-available data, perhaps from a response cache.
Bi-modal Behavior and Static Stability
Distributed systems can suffer from cascading failures that are difficult to manage and predict. Something as simple as a network timeout impacting one component could have unexpected consequences on other components, increasing load, or causing failures, which could then continue to cascade. This sort of behavior is called “bi-modal,” because a system will have different behaviors under normal and failure modes. Ideally, we should be designing components to function well in isolation, implementing “static stability.”
Operational Considerations for Availability
Last month, we reviewed the Operational Excellence Pillar of the Well-Architected Framework. In addition to designing systems that are reliable using the architectural best practices above, you should also implement operational best practices to ensure reliability. All processes, both automated and human, should be designed and documented intentionally, with regular reviews and audits. Let’s discuss a few of the key operational best practices impacting availability.
Automate Deployments to Eliminate Impact
For many businesses, pushing changes to production is a scary operation. Deployment requires the same care and consideration as your software architecture and design, and there are some excellent best practice patterns that you can implement to minimize risk, most of which involve automation:
- Canary deployment – Rather than pushing changes out to an entire customer base at once, a canary deployment pushes changes out to only a small number of users, and then monitors impact before accelerating the deployment to the entire user base.
- Blue-Green deployments – Similar to canary deployment, blue-green deployments involve deploying two complete versions of your application in parallel (blue and green) and then sending traffic fractionally between the two deployments.
- Feature toggles – Creating runtime configuration options to enable and disable new features is another common pattern for deployment. This enables you see the impact of a change in production and quickly disable the feature in the event of a disruption without requiring a rollback.
Above all, your deployment process should be fully automated, with changes run through continuous integration pipelines.
Testing
The higher your availability goals, the more effort you should invest in testing – unit tests, load tests, performance tests, and failure simulations, across many sources of potential failure. Some test modes to consider:
- External dependency availability
- Deployment failures
- Increased latency on critical services
- Degraded or total loss of networking
- DNS failures
Build these tests into your automated testing suite and schedule regular game days to put your procedures to the test.
Monitoring and Alarming
Monitoring is a critical aspect of reliability, as it enables you to detect problems before your customer. Effective monitoring requires gathering data at multiple levels, aggregating it, and surfacing insights based upon that data. AWS encourages deep instrumentation across every layer of your application, including monitoring external endpoints from remote locations. AWS outlines five distinct phases for monitoring: generation, aggregation, real-time analytics and alarming, storage, and analytics.
Generation
The generation phase is the foundation for monitoring your workloads. In this phase, you will:
- Identify which components of your workload require monitoring.
- Define key metrics to track for each component.
- Create alarms based upon appropriate thresholds for your metrics.
AWS provides a large number of services and features which can be useful to capture logs and key metric data, including Amazon CloudWatch, VPC Flow Logs, AWS CloudTrail, and many more.
Aggregation
Effective monitoring requires you to not only instrument your applications and collect data, but also to aggregate that data to extract key metrics. You can use Amazon CloudWatch and Amazon S3 as aggregation and storage layers, and from there define filters to create your metrics.
Real-Time Processing and Alarming
Generating alerts from your metrics is important, including escalation to operators using services like Amazon SNS and Amazon SQS. That said, you should also leverage your alerts to help your application heal itself using Auto Scaling, and AWS Lambda functions that can react to change dynamically.
Storage and Analytics
Aggregating and storing your log data in Amazon S3 enables processing and analytics through services like Amazon Athena, Amazon Redshift Spectrum, and AWS QuickSight. In addition, S3 provides flexible lifecycle rules that will help you transition data to Amazon Glacier for long-term storage, and then expire the content at the conclusion of your retention period.
Operational Readiness Reviews
AWS suggests regular Operational Readiness Reviews, or ORRs, to make sure that applications are ready to go to production. An ORR will initially include checklists outlining operational requirements, but will incorporate lessons learned and best practices from other applications over time. ORRs should be repeated at least once per year.
Auditing
Your investment in effective monitoring should also be protected by regularly auditing your monitoring systems. AWS conducts weekly meetings to review operational performance and to share learnings.
Conclusion
Designing reliable, highly available applications is a daunting endeavour. I hope that the best practices introduced in the Well Architected Framework that we’ve reviewed here will help you along your journey. If you’d like to learn more about the AWS Well-Architected Framework, checkout our webinar on the Reliability Pillar.
As an AWS Well-Architected Review Launch Partner, Mission processes assurance for your AWS infrastructure, processing compliance checks across the five key pillars. Reach out to Mission now to schedule a Well-Architected Review.
FAQ
- How can organizations balance cost and reliability, especially when high availability might increase expenses?
Organizations can balance cost and reliability by adopting a strategic approach that involves understanding the cost implications of different AWS services and configurations. By leveraging AWS's elasticity and scalable resources, organizations can design cost-effective and reliable systems. Prioritizing investments in critical components that require high availability and using cost-optimization tools provided by AWS can also help manage and reduce expenses without compromising reliability.
- What role do automated testing and deployment play in maintaining the reliability of AWS-based applications, according to the framework?
- Automated testing and deployment play a crucial role in ensuring the reliability of AWS-based applications by enabling continuous integration and continuous delivery (CI/CD) practices. These practices help identify and address issues early in the development cycle, reducing the risk of failures in production. Automation also ensures consistent deployment processes, minimizing human errors and facilitating rapid recovery in case of failures, thus maintaining the overall reliability of applications.
- How does AWS recommend handling transient failures or service disruptions to maintain application reliability?
- AWS recommends handling transient failures or service disruptions by designing applications to be resilient. This involves implementing retry logic with exponential backoff strategies for operations that fail, designing for fault tolerance by using AWS services that automatically replicate data across multiple Availability Zones, and preparing for disaster recovery by having a well-planned strategy that includes regular backups and the ability to recreate resources in a different region if necessary quickly.
Go Back



Share this post