Amazon Redshift is a specialized data warehouse that allows users to run unified analytics using a lakehouse architecture. With Amazon Redshift, you can use real-time analytics and artificial intelligence/machine learning (AI/ML) use cases without re-architecture, as the warehouse is both fully integrated with your existing data warehouse and other specialized data stores, such as Amazon Aurora. Supported file formats include Parquet, JSON, ORC, Avro, and connecting with Hudi. The introduction of Amazon Redshift ML allows users to run AI/ML workflow within Redshift itself, eliminating the need for external executions using simple SQL statements.
By utilizing stored procedures within Amazon Redshift, you can efficiently manage a data warehouse and reduce query times. Alternatively, you can import and translate existing stored procedures living in other warehouses (such as a Microsoft SQL server). In the latter case, Amazon’s Schema Conversion Tool (SCT) can automatically translate your stored procedures, reducing manual effort during migrations.
To help you get started, this article shows you how to create and call stored procedures in Amazon Redshift. All you need to follow along is some basic SQL or programming experience.
Why Use Stored Procedures?
A stored procedure is a user-defined routine that’s stored in your database and executed by external applications. That way, you can easily reuse the same series of instructions. Using stored procedures has several benefits:
- Encapsulation: If your application has complex or frequently-used queries, you can encapsulate it into a stored procedure that accepts a few parameters. That way, you don't have to send it across the wire every time you want to use it.
- Access control: You can grant users permission to execute a stored procedure that retrieves or updates specific fields, without giving full access to underlying tables.
- Maintainability: It's easier to manage a stored procedure on the database server than to maintain a series of queries in the application code.
- Data validation: A stored procedure that saves data can have safeguards to ensure it only stores valid data. Think of this as your last line of defense to catch errors missed at the application layer.
- Business logic: Business logic usually lives in applications, not the database. However, you can put reads and writes behind stored procedures, applying the same business logic regardless of which application or user is working with the data.
- Data transformation and combination: If your applications frequently need several queries to get their information, or need to transform data into another format, consider doing this work in a stored procedure. That way, the application receives exactly what it needs. This is also in line with encapsulation and keeps all data-related logic in the database.
Here's a simplified illustration of the mechanics of using stored procedures in your environment whether you are connected via a sql workbench, visualization tool like Amazon QuickSight, or simply pushing/pulling data through an AWS Lambda function. The stored procedure contains all of the queries, operations, and logic needed to return useful information to the connected service in a consistent fashion. The connected service simply calls the stored procedure. The stored procedure makes any queries or executes any operations required, then returns a result, if applicable, to the application.
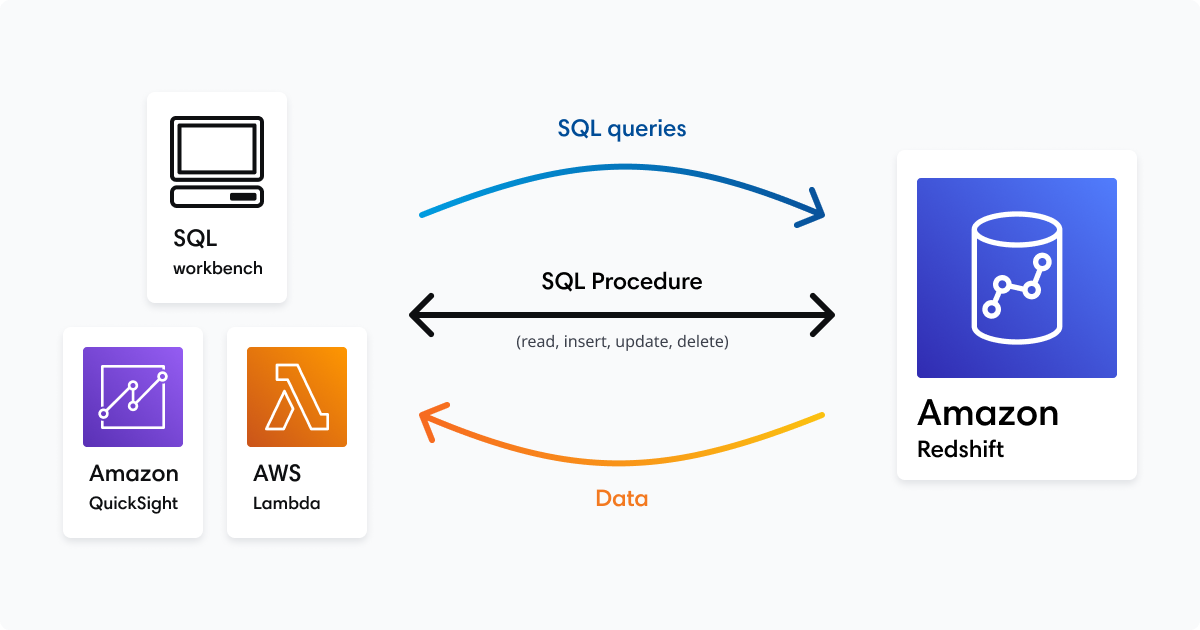
There are several advantages here:
- First, the connected service does not require any knowledge of the stored procedures other than how to call them.
- Second, if the operations need to change, you only need to update the stored procedure, not the connected service.
- Third, you can configure security and privileges for stored procedures separate from the security and privileges for the connected service.
Creating Stored Procedures
Create a stored procedure using the CREATE PROCEDURE command. The global syntax looks like:
CREATE PROCEDURE name(<argument list>) AS $$
DECLARE
<variable declarations: name and data type>
BEGIN
<instructions>
END
$$ LANGUAGE plpgsql;
If you don't wish to declare any variables, you can leave the DECLARE keyword out. Here's an example of a simple stored procedure, without arguments or variable declarations:
CREATE PROCEDURE hello_world() AS $$
BEGIN
RAISE NOTICE 'Hello, world!';
END
$$ LANGUAGE plpgsql;
When this stored procedure is called, it prints a notice "Hello, world!" We'll take a closer look at calling stored procedures in the next section, though you can try it out with the command CALL hello_world();.
To overwrite an existing procedure, use the same syntax and replace CREATE PROCEDURE by CREATE OR REPLACE PROCEDURE. You can only use that command when the argument list is the same as before. If it's not, you have to use DROP PROCEDURE name(<argument list>) first.
Let’s create a stored procedure with some parameters now. The argument list is comma-separated, and every argument has a name, argument mode, and data type. The argument mode is either IN, OUT, or INOUT. If omitted, it's IN. As their names imply, IN is for input arguments and OUT is for output arguments. Use these to pass the return value(s) to the caller. INOUT arguments are both input and output.

To assign a value to a variable, use the name := expression syntax. This works alike for output arguments and variables declared in the DECLARE block. The expression after := is like a SELECT query - just without the SELECT keyword. (Note, however, that you cannot do something like name := * FROM table WHERE id = 5;. This needs the SELECT … INTO syntax, which we will look at later in this section.)
As an example, we’ll create a stored procedure that takes a number n as input and returns the nth Fibonacci number as output. This example demonstrates variable declarations, an input parameter, and an output parameter.
CREATE PROCEDURE fibonacci(n IN INT, result OUT INT) AS $$
DECLARE
phi DOUBLE PRECISION;
psi DOUBLE PRECISION;
temp DOUBLE PRECISION;
BEGIN
phi := (1 + SQRT(5)) / 2;
psi := (1 - SQRT(5)) / 2;
temp := (POWER(phi, n) - POWER(psi, n)) / SQRT(5);
result := ROUND(temp)::integer;
END
$$ LANGUAGE plpgsql;
As you can see, you can use all built-in Amazon Redshift functions in your stored procedure, such as SQRT, POWER, and ROUND. (You can also use any other statements, such as UPDATE or INSERT INTO.) The last statement also casts the value into an integer and stores it in the result variable, the output.
Instead of the returned procedure returning scalars (strings, numbers, booleans, and more), it can return a cursor. To do that, use an INOUT argument of the data type refcursor. To store the cursor in that variable, use the syntax OPEN <argument name> FOR <query>. Here's an example:
CREATE PROCEDURE cheaper_than(given_price IN INT, result INOUT refcursor) AS $$
BEGIN
OPEN result FOR SELECT * FROM products WHERE price < given_price;
END
$$ LANGUAGE plpgsql;
Another way to return a set of results is by creating a temporary table that the caller can query.
CREATE PROCEDURE table_cheaper_than(given_price IN INT, tbl_name IN VARCHAR(128)) AS $$
BEGIN
EXECUTE 'DROP TABLE IF EXISTS ' || tbl_name;
EXECUTE 'CREATE TEMP TABLE ' || tbl_name || ' AS SELECT * FROM products WHERE price < ' || given_price;
END
$$ LANGUAGE plpgsql;
We will look at how to call these procedures and use their results in the next section.
Let’s now look at conditional statements in the stored procedures: for example, IF and CASE. The basic syntax for an IF statement is:
IF <condition> THEN
<statements>
END IF;
Expanded with ELSIF and ELSE, it looks like:
IF <condition> THEN
<statements>
ELSIF <condition> THEN
<statements>
…
ELSE <condition> THEN
<statements>
END IF;
As an example, let’s expand our Fibonacci procedure to always return zero if the argument n is zero or below:
CREATE PROCEDURE fibonacci2(n IN INT, result OUT INT) AS $$
DECLARE
phi DOUBLE PRECISION;
psi DOUBLE PRECISION;
temp DOUBLE PRECISION;
BEGIN
IF n > 0 THEN
phi := (1 + SQRT(5)) / 2;
psi := (1 - SQRT(5)) / 2;
temp := (POWER(phi, n) - POWER(psi, n)) / SQRT(5);
result := ROUND(temp)::integer;
ELSE
result := 0;
END IF;
END
$$ LANGUAGE plpgsql;
For CASE statements, there are two forms:
- Simple CASE: CASE … WHEN … THEN … ELSE … END CASE
- Searched CASE: CASE WHEN … THEN … ELSE … END CASE
When using a simple CASE, you provide a variable to compare with the given values, so the appropriate WHEN block is executed. Here is an example:
CASE x
WHEN 0 THEN
-- x is zero
WHEN 1, 2, 3 THEN
-- x is one, two, or three
ELSE
-- x is not zero, one, two, or three
END CASE;
When using a searched CASE, you don’t provide a variable, only a boolean expression for each WHEN, like this:
CASE
WHEN price < 5 THEN
…
WHEN price < 50 THEN
…
ELSE
…
END CASE;
This behaves exactly like a sequence of IF and ELSIFs: the first truthy WHEN block is executed, and any following WHEN blocks are skipped. So, for example, in the above CASE statement, if price is 4, only the price < 5 block is executed - the price < 50 block (and any others) are skipped.
CREATE OR REPLACE PROCEDURE test1(given_price IN INT, result OUT INT) AS $$
DECLARE
temp record;
BEGIN
SELECT * INTO temp FROM products WHERE price < given_price LIMIT 1;
result := 1;
END
$$ LANGUAGE plpgsql;
Inside a stored procedure, you’ll often want to work with records from tables. This is what the RECORD data type is for. It either contains a single row and record or NULL. You can declare a record variable in the DECLARE block. Fields on a variable in the record type can be accessed by variable_name.field_name. (Note that RECORD is not a valid parameter type, so you cannot use it to return a single row from a stored procedure. You still have to use refcursor or temporary table methods, as seen earlier.)
Here’s an example of loading a row into a RECORD variable:
CREATE PROCEDURE record_example(given_id IN TEXT) AS $$
DECLARE
rec record;
BEGIN
SELECT * INTO rec FROM products WHERE id = given_id;
RAISE NOTICE 'price: %', rec.price;
END
$$ LANGUAGE plpgsql;
When you must handle multiple records as a result of the same query, use a FOR loop, like this:
CREATE PROCEDURE record_loop_example() AS $$
DECLARE
rec record;
BEGIN
FOR rec IN SELECT * FROM products LOOP
RAISE NOTICE '% with price %', rec.id, rec.price;
END LOOP;
END;
$$ LANGUAGE plpgsql;
Lastly, we’ll look at how to set permissions on a stored procedure. You can only call a procedure if you are granted its EXECUTE permission. By default, only the procedure owner and superusers have this permission. To grant permission to another user, use the GRANT command:
GRANT EXECUTE ON PROCEDURE procedure_name(<argument list>) TO user;
The argument list is required because stored procedure names can be overloaded. Providing argument names isn’t necessary here. The mode and type are enough. For example: fibonacci(IN INT, OUT INT).
To revoke a permission again, use the REVOKE command, which has almost the same syntax as GRANT, only the TO becomes a FROM, logically.
For more GRANT command options, refer to the Amazon Redshift documentation about GRANT.
Stored procedures also have a SECURITY attribute, which is either DEFINER or INVOKER. The default is INVOKER. This means the procedure runs with the user’s privileges. If a procedure is SECURITY DEFINER, the procedure runs with the privileges of its owner. Set the SECURITY attribute at the end of the CREATE PROCEDURE command:
…
$$ LANGUAGE plpgsql
SECURITY DEFINER;
Find more details, and guidelines to prevent SECURITY DEFINER procedure misuse, in the Amazon Redshift documentation about stored procedure security.
Calling Stored Procedures
Execute a stored procedure using the CALL command, which looks like this:
CALL procedure_name( <input arguments> );
For example, for our Fibonacci procedure:
CALL fibonacci(8);
The output is a row of all OUT arguments. For our Fibonacci procedure, there is only one value because there is only one OUT argument. For procedures with multiple OUT arguments, the column names of the returned row are the names of the OUT arguments.
Calling procedures that return a cursor or a temporary table requires some extra attention. You can only use the cursor or temporary table within transactions (so BEGIN; <statements>; END;).
When calling a procedure returning a cursor, for the refcursor argument, you must pass a string. This string will name the cursor. You can then access records from the cursor using FETCH:
BEGIN;
CALL cheaper_than(50, 'product_cursor');
FETCH 10 FROM product_cursor;
END;
On multi-node Amazon Redshift clusters, use FETCH ALL. On single-node clusters, the limit is 1,000.
Calling a procedure that returns a temporary table works similarly:
BEGIN;
CALL table_cheaper_than(50, 'product_table');
SELECT * FROM product_table;
END;
Next Steps
Creating stored procedures in Amazon Redshift is efficient and effective when you have the requisite SQL or programming experience. Although you can do a lot with what you’ve learned here, here are additional resources to help you dive deeper:
If you want to start creating and using Amazon Redshift stored procedures but aren’t sure where to start, read more about the ways Mission Cloud helps with data and analytics on AWS.
FAQ
How can you optimize the performance of stored procedures in Amazon Redshift for large datasets?
Optimizing the performance of stored procedures in Amazon Redshift, especially when working with large datasets, is a critical concern for database administrators and developers aiming to ensure efficient data processing and query execution. The key to optimization lies in understanding and leveraging Redshift's columnar storage and massively parallel processing (MPP) architecture. One effective strategy is to minimize the volume of data being processed by filtering rows early in the procedure using WHERE clauses. Additionally, incorporating SORT and DIST keys in your table design can significantly reduce query execution times by aligning the data structure with common access patterns. Avoiding excessive looping and complex computations within stored procedures is also advisable, as these can lead to performance bottlenecks. Instead, consider breaking down complex operations into simpler steps and using temporary tables to store intermediate results. Monitoring and analyzing query performance using Amazon Redshift's system tables and views can provide insights into potential optimizations, allowing for continuous improvement of stored procedure efficiency.
Are there any limitations or best practices regarding the nesting of stored procedures in Amazon Redshift?
When it comes to nesting stored procedures in Amazon Redshift, it's important to approach this practice cautiously to maintain code clarity and prevent potential performance issues. While Redshift supports the nesting of stored procedures, doing so can introduce complexity, making the procedures harder to debug and maintain. Best practices suggest keeping stored procedures as modular and simple as possible, focusing on achieving a single task efficiently. If nesting becomes necessary, ensure that each procedure has a well-defined purpose and that the nesting depth is kept to a minimum to avoid confusion and potential execution plan inefficiencies. Documenting the logic and flow between nested procedures extensively is also crucial for future maintenance and understanding by other team members. Regular review and refactoring of nested stored procedures can help identify opportunities to simplify the logic or decompose overly complex procedures into more manageable components.
How can stored procedures be integrated with other AWS services for advanced analytics and data processing workflows?
Integrating stored procedures in Amazon Redshift with other AWS services opens up many opportunities for building advanced analytics and data processing workflows. Stored procedures can be a powerful tool for pre-processing data, enforcing business logic, and preparing datasets for analysis. For instance, a stored procedure in Redshift could be used to aggregate and transform data, which can then be exported to Amazon S3 using the UNLOAD command for further processing or analysis in other AWS services like Amazon Athena or Amazon EMR. Additionally, AWS Lambda functions can be triggered by events in Redshift or S3, allowing for serverless processing workflows that can scale automatically with the data volume. This integration can be particularly useful for implementing ETL pipelines, real-time analytics, and data warehousing solutions. By leveraging the strengths of each AWS service, developers can create highly scalable, efficient, and flexible data processing architectures that meet the complex needs of modern data-driven applications.