Migrating existing HPC workloads to the cloud can be a daunting experience, where engineering teams are often forced to choose between retooling their existing workloads to work on a cloud-native scheduling platform, or managing the overhead of deploying and maintaining the infrastructure required to run their jobs in the cloud.
What is AWS ParallelCluster?
AWS ParallelCluster is a tool, built on the open-source CfnCluster project, built to streamline the process of deploying HPC clusters on AWS, via either Slurm (an open sourced scheduler that can run jobs on EC2 instances), or Batch (an AWS-managed solution that’s oriented towards containerized workloads). This article will focus on using ParallelCluster to deploy Slurm workloads.
Here are some of the advantages of deploying Slurm clusters via ParallelCluster:
-
Simplified cluster deployment: ParallelCluster will deploy standard AWS resources to create and bootstrap a Slurm cluster, while following best practices for security and ease of administration. Clusters can be easily deployed, updated, and destroyed in a repeatable, predictable manner, and the cluster spec can be integrated with existing Infrastructure as Code solutions.
-
Extreme scalability: Slurm clusters deployed with AWS ParallelCluster can temporarily provision EC2 instances that meet the performance requirements of your workloads, then destroy them when not in use. You only pay for the compute time you use, which means you can experiment with various types of hardware, and only pay for the most expensive compute types when they’re needed.
-
Native integration with AWS services: ParallelCluster seamlessly integrates with other commonly used AWS services, like S3, RDS, AWS Secrets Manager, Elastic Fabric Adapter, and a variety of networked storage solutions (detailed at the end of this article).
-
Compute flexibility: Run your workloads on a wide variety of supported Linux operating systems, hardware configurations, and processor architectures, using either on-demand or spot instances.
Architectural Overview
A standard deployment consists of the following components:
-
Head node: The Head node (or nodes, if using a federated multi-cluster architecture) is the centralized brain of the cluster. It runs a number of critical services for the cluster to function, including:
-
slurmctld: The central management daemon, used to accept/route jobs to the appropriate queues, as well as monitor all other Slurm daemons on the cluster
-
slurmdbd: Used to store job info in a central database, (which can be hosted in RDS)
-
-
Compute node queues: Multiple job queues can be configured, which allows jobs to be run on various compute types based on their requirements. Compute instances are ephemeral, and can be autoscaled down to zero nodes, so you don’t pay for unused compute time when no jobs are being run
-
Accounting database: AWS offers an optional extension, which creates a serverless RDS database, which can be passed into the cluster YAML specification. This will configure the slurmdbd to store all job accounting data in an AWS-managed database
-
Login nodes (optional): Logging directly into the head node to submit jobs should be discouraged. The native ParallelCluster approach to enabling users to submit jobs involves the use of Login nodes, which can be accessed via SSM or SSH, and used to submit jobs to the head node, while having no access to the critical processes running on the Head node.
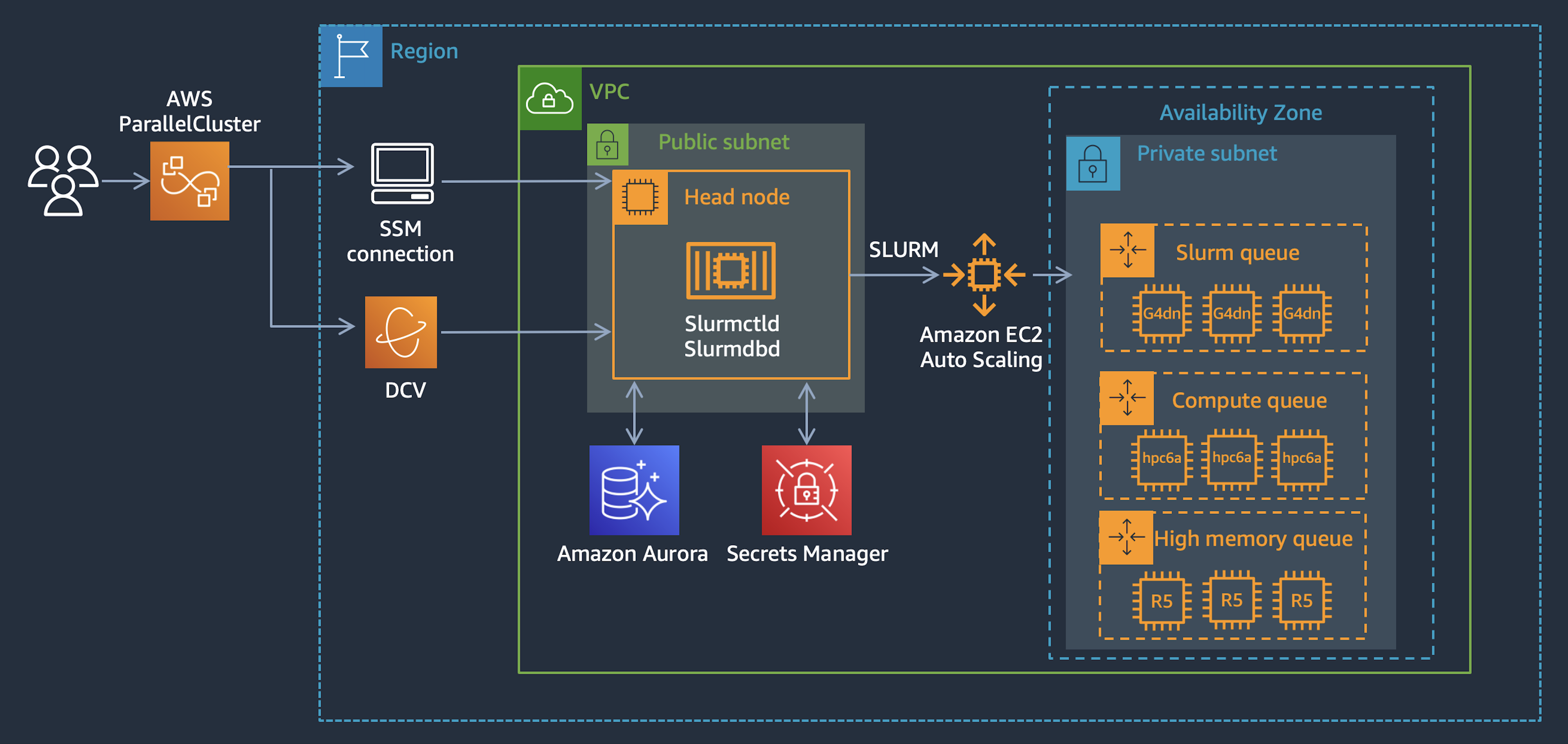
System diagrams provided by AWS. Note that the Head node can run in either public or private subnets, and that Login nodes are not being used.
Deployment Methods
ParallelCluster UI (Good)
This is the simplest solution to spin up proof-of-concepts with ParallelCluster. An official AWS CloudFormation template can be used to deploy a web application, which provides a guided visual interface that can be used to build a cluster that suits your needs.
ParallelCluster CLI Application/API (Better)
While the ParallelCluster UI is convenient, the deployment/upgrade process is entirely manual, and changes to the cluster YAML config cannot be tracked in a Git repository as Infrastructure-as-Code. Fortunately, ParallelCluster offers an API, as well as a CLI which can be used to programmatically administer clusters, which allows you to implement DevOps best practices across all of your AWS infrastructure.
EDA-Specific Solution (Best)
The engineers at Annapurna Labs (the lab in which AWS develops it’s own custom silicon) have developed an open-sourced CDK (Cloud Development Kit) application, which helps drastically simplify and accelerate the process of deploying a production-ready cluster that is optimized for EDA workloads, where jobs can scale out across hundreds (or thousands) of compute nodes, requiring some additional considerations to be taken. This solution has been used in production at Annapurna since 2020.
Some (but not all) of the added benefits of deployment using this method include:
-
Enhanced integration with Scale-out Computing on AWS (SOCA): The head node is configured to allow SOCA workstations to be configured as Slurm job submitters, which bypasses the requirement to deploy Login nodes for each team member who will submit jobs to the cluster.
-
For more information about SOCA, visit this repository
-
-
Directory integration at scale: The Slurm cluster can sync users/groups with an existing Active Directory/OpenLDAP directory, without joining Slurm nodes to the directory. This helps circumvent possible stability issues that can arise when joining hundreds (or thousands) of compute nodes to a directory at the same time when running large jobs
-
Simplified license management: License-aware scheduling can be setup to work with a fixed number of licenses, which are accounted for by the cluster
You can read more about Annapurna’s solution in this public AWS article.
Choosing the Right Storage Solution for Your Cluster
There is no one-size-fits all storage solution we can recommend by default, as different workloads will have different performance/compatibility requirements. Luckily, ParallelCluster offers native support for a number of AWS storage services, detailed below:
EBS: Elastic Block Storage
EBS volumes can be mounted to the head node, and shared with the queue nodes via NFS. While this could be suitable for a proof-of-concept, it’s not recommended for production workloads, due to a lack of resiliency, colocation with head node services, and no AWS-native backup capability.
EFS: Elastic File System
Elastic File Share is an elastic, managed network filesystem, which can be mounted to all nodes in the cluster. It’s a fully elastic service, which means you only pay for the storage you use. While very flexible and budget-friendly when compared to the solutions detailed below, it’s not designed for workloads that require extreme throughput, or the ability to quickly read small files very rapidly.
FSx for Lustre
Lustre can process massive data sets at up to hundreds of gigabytes per second throughput, millions of IOPS, and sub-millisecond latencies. It’s optimized for scale-out workloads which require the prioritization of performance over value and elasticity.
Some notable downsides are as follows:
-
Only compatible with Linux
-
Tightly coupled with AWS S3 for loading and managing data
FSx for ONTAP
Amazon FSx for ONTAP provides fully managed shared storage in the AWS Cloud with the popular data access and management capabilities of NetApp ONTAP. It serves as a drop-in replacement for existing NetApp deployments.
FSx for OpenZFS
Amazon FSx for OpenZFS provides fully managed shared file storage built on the OpenZFS file system and accessible through the NFS protocol (v3, v4, v4.1, and v4.2). It’s optimized for latency-sensitive and small-file workloads, and offers data management capabilities like snapshotting, cloning, replication, and compression.
Conclusion
While we’ve discussed the technical details at a very high level, there is still so much more to learn. Hopefully you’re better equipped to dive deep into the world of High Performance Computing on AWS, transform the way you run EDA workloads!
More Resources
-
AWS
-
Slurm