This article is part of an ongoing series taking a deep look at Amazon’s Well-Architected Framework, which is an incredible collection of best practices for cloud-native organizations. This month, we’re digging into the Cost Optimization Pillar.
As businesses make the transition to the cloud and away from on-premise infrastructure, one of the hottest topics of conversation is TCO. Because cloud represents a tectonic shift in how infrastructure is procured and consumed, a whole new approach to cost management is required. Navigating this shift isn’t easy, but thankfully, best practices have emerged that will help guide you down the right path.
The AWS Well-Architected Framework is a comprehensive collection of best practices for maximizing the cloud across five key pillars, and this month, we’ll be focusing on the Cost Optimization pillar, which introduces itself thusly:
This paper focuses on the cost optimization pillar and how to architect systems with the most effective use of services and resources, at a minimal cost. You’ll learn how to apply the best practices of the cost optimization pillar to your solutions. Cost optimization can be challenging in traditional on-premises solutions because you have to predict future capacity and business needs while navigating complex procurement processes.
The best practices outlined in the Cost Optimization pillar are designed to help organizations design and implement their systems that:
- Closely align cost with actual demand.
- Use the proper AWS resources to achieve business goals cost effectively.
- Enable granular and deep cost attribution and analysis.
- Become more efficient and cost effective over time.
A company that embraces the cost optimization best practices outlined within the Well-Architected Framework will have:
- High transparency at all layers for where infrastructure spend is going – by product line, business unit, customer, etc. – and a drive to use that information to drive efficiencies.
- Product teams that are given ownership of their infrastructure and then held accountable for their infrastructure costs.
- Applications and systems that can change their infrastructure consumption based upon usage and business requirements.
Let’s dive into the Cost Optimization Pillar of the Well-Architected Framework to learn more about the best practices contained within.
If you’re interested in learning about the birth of the AWS Well-Architected Framework, then check out our initial post, “Introducing the AWS Well-Architected Program.”
Design Principles
Amazon outlines five design principles for cost optimization in the cloud:
- Adopt a consumption model
- Measure overall efficiency
- Stop spending money on data center operations
- Analyze and attribute expenditure
- Use managed services to reduce cost of ownership
Adopt a Consumption Model
In 2006, Amazon introduced S3 and EC2, pioneering what we now call “cloud.” One of the key innovations of S3 and EC2 was utility billing, which enables businesses to transition from a CapEx model to an OpEx model, and to closely align their costs with their consumption. Yet, many businesses are not yet taking full advantage of the consumption model, instead opting to operate static workloads in the cloud in a similar fashion to how they ran those same workloads in their data centers.
This design principle calls for fully embracing the consumption model that AWS enables by closely aligning infrastructure spend with business requirements, scaling infrastructure up and down, and picking the proper resource types. One example that AWS cites in the white paper is the ability to stop development and test environments during non-working hours for a potential cost savings of 75% (40 hours vs. 168 hours).
Measure Overall Efficiency
Understanding the “business output” of a system is a critical component of developing a complete picture of your business, especially when you combine that insight with the costs required to deliver that output. Understanding your overall system efficiency will empower you to make better decisions.
Stop Spending Money on Data Center Operations
This design principle should come as no surprise: AWS recommends fully embracing the cloud, leaving the heavy lifting of data center operations to them. By getting out of the data center, you free up resources and brainpower to focus on your customers and creating business value.
Analyze and Attribute Expenditure
Tracking expenditures in the data center can be enormously challenging, with applications deployed to fixed-size hardware, and the need to allocate costs for things like power, cooling, and management. In addition, large-scale capital expenditures must be somehow broken down to accurately reflect the cost of delivering specific workloads. In the cloud, you have the ability to track costs in a much more granular way. By breaking down costs and assigning them to specific product teams and business owners, you can enable them to optimize and reduce cost.
Use Managed Services to Reduce Cost of Ownership
AWS’ relentless customer-driven approach to operating their business has resulted in massive growth, and a big part of being customer-driven is focusing on delivering value to the end customer by leveraging your core strengths. Rather than focusing on managing infrastructure, businesses should follow AWS’ lead, and find ways to spend more time delivering value to their customers. With this design principle, AWS encourages customers to take advantage of managed services that greatly reduce time and effort spent on infrastructure management.
What are managed services? AWS provides several managed cloud services that abstract away servers, and instead focus on delivering a specific function/feature as a service. Notably, AWS provides managed relational databases with RDS, where the service provides full access to relational databases without the need to manage the underlying infrastructure. In addition, managed service providers like Mission can provide the management of the rest of your infrastructure, freeing you up to focus on innovating for your customers.
Cost Optimization Focus Areas
AWS breaks down cost optimization in the cloud down into four key areas of focus:
- Cost-effective resources
- Matching supply with demand
- Expenditure awareness
- Optimizing over time
Let’s dive deep into each area of focus to better understand the best practices contained within the Well-Architected Framework.
Focus Area: Cost-Effective Resources
AWS offers many different services, including multiple configurations and ways to purchase those services. Using them appropriately is a critical aspect of optimizing your spend. AWS breaks down this focus area into five approaches: appropriate provisioning, right sizing, purchasing options, geographic selection, and managed services.
We’ll walk through each of these approaches, but it’s important to note that AWS encourages its customers to consider using an Amazon Partner Network (APN) Partner to help guide architecture and optimization decisions.
Appropriate Provisioning
AWS’ services, including its managed services like RDS and EMR, provide many attributes and configuration parameters that impact capacity and performance. Appropriate provisioning is all about setting and then continuously adjusting these attributes to deliver your performance goals with the minimum capacity.
Attributes such as the number of nodes in an Amazon EMR cluster or the backing instance size for an RDS instance can be modified using the AWS Console, but its generally best practice to use AWS APIs and SDKs to change these attributes in lockstep with changes in demand. Mission provides this management on behalf of our customers using continuous monitoring and automation driven by Infrastructure as Code tools like Terraform and CloudFormation.
In addition to proper configuration, provisioning can be impacted via “resource packing.” For example, when creating an RDS instance, it is possible to create multiple databases within a single instance in the event that you have adequate capacity. If usage increases, databases can be easily migrated to their own RDS instances to meet performance requirements.
While configuration and resource packing are useful, it’sits important to note that adjusting configuration and “unpacking” resources when the need arises will have consequences: time to make adjustments or migrations and potential impacts to system operation. AWS recommends measuring these impacts and taking them into account when provisioning resources. You may even consider slightly over-provisioning to give yourself wiggle room when making these adjustments.
To minimize impact and reduce effort for our Managed Cloud customers, Mission implements monitoring and automation to scale systems automatically based upon demand. Amazon CloudWatch is a key service to leverage for collecting and tracking metrics to enable automation.
Right Sizing
AWS defines right sizing as “using the lowest cost resource that still meets the technical specifications of a specific workload.” Those technical specifications should be calculated based upon business need and requirements. As business requirements evolve, so may these technical specifications. In addition, other external factors may drive changes in technical requirements: AWS price drops, new AWS services and resource types, and customer demand. As a result, an iterative approach is best when adjusting the size of resources to optimize spend.
Mission’s focus on automation has found its way to “right sizing” as well, and we use AWS APIs to modify resources in response to demand. That includes changing EC2 instance sizes/types, moving to EBS volumes with provisioned IOPS, etc. In some cases, its best to create alarms that trigger an evaluation before implementing the change.
AWS outlines three key considerations for right-sizing exercises:
- Monitoring must accurately reflect the end-user experience. Look beyond simple averages, and take into account maximums, and 99th percentiles, to ensure that you’re properly capturing the end-user’s experience.
- Evaluate the correct time period. If you’re too granular, you may miss spikes that are outside the window of evaluation, leading to under or over provisioning.
- Carefully balance the cost of modification against the benefit of right sizing. A detailed cost/benefit analysis will help you prioritize.
Purchasing Options
For many workloads, cost is driven primarily by compute costs. Amazon EC2 provides a number of purchasing models for EC2 instances, and properly employing all three purchasing models is necessary to meet your business goals in the most cost-effective way. Mission provides continuous Cloud Optimization as a service for our customers, and much of our efforts go into helping guide these purchasing decisions based upon our extensive experience across hundreds of customers and workloads.
Let’s review the three purchasing models for EC2 instances: On-Demand, Spot, and Reserved.
On-Demand Instances
On-Demand is the default purchasing model for EC2 instances. In this model, a flat hourly rate is charged for EC2 instances based upon the type and size of the instance, with no up-front cost, and no long-term commitment. Because of their higher overall cost, On-Demand Instances are recommended for unpredictable/spiky and short-term workloads, or dev/test environments.
In our years of experience helping customers optimize their cloud spend, we’ve found that over-use of On-Demand Instances is the most common mistake that companies make when moving to AWS.
Spot Instances
Spot Instances are procured through an auction-like system, allowing you to place bids on unused EC2 capacity. Spot Instances can lower your EC2 costs by up to 90% compared to On-Demand Instances. To bid on Spot Instance capacity, you set a maximum price that you’re willing to pay for an instance, and when your bid meets or exceeds the current Spot price, your request is fulfilled and your instances will be automatically provisioned. If the Spot price rises above your bid price, you will receive a two-minute warning, and then your Spot Instance will be terminated and reclaimed. Spot Instances can also be requested with a minimum required duration, known as a “Spot block,” with savings up to 45% of On-Demand Instances.
Because of the dynamic nature of Spot Instances, they’re most useful for use cases like batch processing, image or video processing, financial analysis, and testing, and the use of them using Spot Instances requires your applications to react to Spot Instance Termination Notices.
Spot Instances can also be launched in larger groups using Spot Fleet, which is a collection of Spot Instances that are working together as part of a distributed application, such as a large batch-processing job.
AWS recommends that you consider three main factors when considering Spot Instances:
- Instance type Because prices will vary by family, size, and type, its best to place bids with as much flexibility as possible to provide a low cost and chance of interruption.
- Instance location Each AWS Availability Zone is a different market, and a willingness to run your workloads in a number of different regions helps you maximize cost savings.
- Continuity Finally, your application should be architected to properly take advantage of Spot Instances by reacting to potential interruptions elegantly by frequently saving state and terminating gracefully.
Spot Instances with attached EBS volumes, including EBS-backed root volumes, can be set to stop, rather than terminate, when the Spot price exceeds your bid, and the EBS volumes will remain intact. As capacity again becomes available, the instances will be restarted and resume execution without having to start from scratch.
Reserved Instances
The final purchasing model to consider for EC2 instances is Reserved Instances, where EC2 instances are purchased based upon a commitment over a fixed term of one or three years. By committing, you can save up to 75% over On-Demand rates. There are two types of Reserved Instances: standard and convertible.
Standard Reserved Instances require a commitment for a specific instance family, size, and Availability Zone specified, while Convertible Reserved Instances allow for conversion to different families, updated pricing, different instance sizes, etc.
There are three different payment options for Reserved Instances which provide a balance between up-front cost and TCO:
- Reserved Instances that require no up-front payment are colloquially referred to as NURIs, and provide a small discount over On-Demand Instance pricing.
- Reserved Instances with a partial up-front payment (PURIs) provide a much higher discount over On-Demand Instance pricing in exchange for some of the usage being paid in advance.
- Reserved Instances with 100% advance payment up (AURIs) give the highest possible discount over On-Demand Instance pricing.
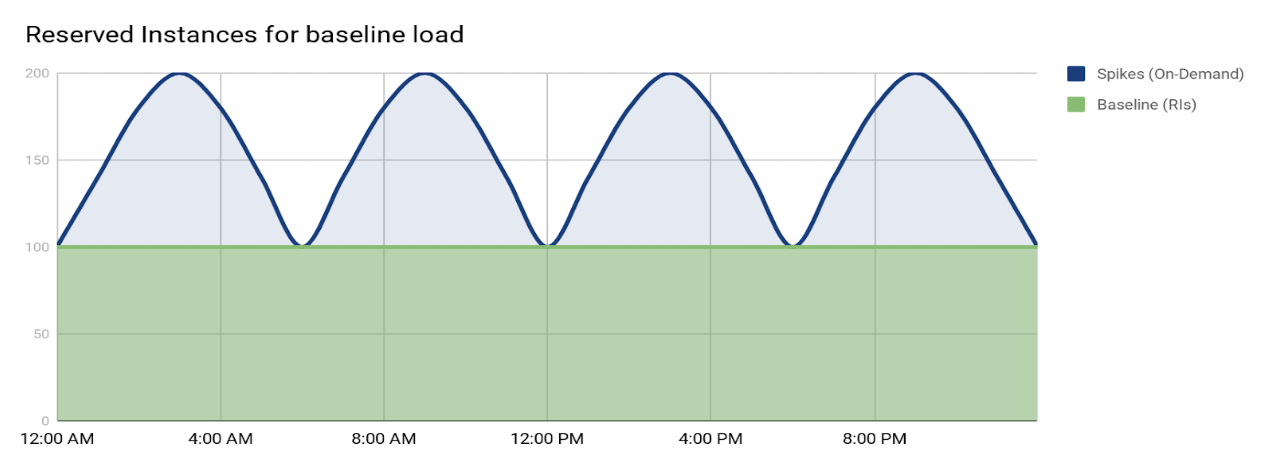
In our experience, Reserved Instances are the best tool in your toolbox for reducing your spend. Many workloads have a baseline, steady-state load that is best served by Reserved Instances, leaving usage spikes to be handled by On-Demand Instances delivered through auto-scaling.
Geographic Selection
AWS provides global Regions and Availability Zones to help you deploy your applications and infrastructure closer to your users to provide the lowest latency, highest performance, and to meet data sovereignty and compliance requirements. If your application has a global reach, you may need to deploy your application in multiple Regions.
That said, because AWS Regions operate within local market conditions, pricing can vary from Region to Region, so consider carefully which Regions to deploy your application, or components of your application, to properly balance cost with performance.
AWS provides useful resources for helping you estimate costs across Regions, including the AWS Simple Monthly Calculator.
Managed Services
Managing servers, configuring software, and other operational tasks required to maintain a service can be a real distraction from the job of innovating for your customers. AWS provides a full suite of managed services and application-level services that remove much of the burden of management from your team. Amazon RDS and DynamoDB provide you with powerful databases as a fully managed service, while AWS Lambda, Amazon SQS, and other application services give you powerful components to build your applications on top of without having to manage any servers, or worry about software licensing. AWS operates these managed services at massive scale, creating significant efficiencies, and driving down cost per transaction, reducing TCO.
In addition to AWS’ managed services, Managed Service Providers like Mission can provide at-scale management of your infrastructure, including site and instance monitoring, alert response, operating system maintenance and updates, instance and database backup, and more.
By taking advantage of AWS managed services and engaging a Managed Service Provider like Mission, you can reduce the cost of managing infrastructure, and apply the time savings to enable your team to focus on creating new products and features to that create business value.
Focus Area: Matching Supply with Demand
On-demand infrastructure in the cloud enables close alignment of “supply” (infrastructure) with “demand” (usage/traffic) in near real time. With a liberal application of metrics and automation, business are able to reduce cost, eliminating the waste from overprovisioning, and meet unexpected spikes in load without human intervention. That said, there are considerations when planning out how to make your environment scale up and down, in and out, to match supply with demand, including high availability, failure scenarios, and provisioning time. Let’s talk about a few approaches to the problem of matching supply with demand in the cloud.
Demand-Based
AWS has designed their services to enable “elasticity” for your applications. By leveraging AWS’s services and APIs, you can create systems that dynamically adjust the size and number of resources in your system in response to metrics and alarms. The primary mechanism to drive these changes in AWS is Auto Scaling, coupled with Elastic Load Balancer (ELB). Using Auto Scaling, you can automatically scale the number of EC2 instances in your system up and down automatically based upon a set of rules. Traffic can then be directed to instances in these Auto Scaling groups using the ELB service. Generally speaking, its best to trigger scale events using CloudWatch metrics and alarms, such as CPU utilization, ELB latency, or custom metrics from your systems.
While AWS does provide virtually unlimited on-demand infrastructure for your applications to scale, provisioning of new resources isn’t instant. It can take minutes for new EC2 instances to be provisioned, for example, and those instances then need to boot and perform any startup or configuration tasks before they can add capacity to your system. Thus, its important to consider provisioning speed when taking a demand-based approach. Consider optimizing the provisioning of EC2 instances for auto-scaling by creating a pre-configured Amazon Machine Image (AMI).
Another consideration for a demand-based approach is that demand can often be quite unpredictable. Coupled with your provisioning time considerations, you should carefully design your auto-scaling conditions to account for dynamic shifts in demand.
Buffer-Based
Some applications are particularly well-suited to a producer/consumer architecture, where demand is represented by incoming messages or requests for work, and supply is represented by compute resources to consume those messages. In such systems, a “buffer-based” approach can help ensure that the system can handle varying rates of incoming messages and processing throughput.
A buffer-based approach decouples the rate at which messages are produced and the rate at which they are consumed, with messages being sent to a durable system to hold unprocessed messages. AWS provides many such services, including Amazon Simple Queue Service (SQS) and Amazon Kinesis.
When using Amazon SQS, you can keep your costs low by having producers publish messages in batches, and by using “long polling” to retrieve messages as soon as they’re available. By default, SQS will ensure that each message will be delivered at least once, and if your application requires assurance that messages are delivered precisely once, you should use SQS FIFO (first in/first out) queues.
Kinesis offers an alternative to SQS for buffering, and is useful in cases where multiple consumers need to be able to read a single message. With Kinesis, you can create publish/subscribe architectures where different component of your system can subscribe to receive the same messages to handle different aspects of processing.
One great way to reduce spend is to leverage EC2 Spot Instances for your consumers, especially when delays in processing can be tolerated. Work can buffer within SQS for Kinesis until inexpensive capacity is available, and then rapidly be processed by a fleet of inexpensive Spot Instances.
A key consideration when taking a buffering approach is how your system reacts to duplicate requests. In many cases, the best approach is to design your system for idempotent processing, where a message can be processed multiple times with no side effects.
Time-Based
Some workloads have highly predictable capacity demands that are well-defined by time. In such cases, a time-based approach is superior to a demand-based approach because you can greatly reduce the impacts of provisioning time.
AWS Auto Scaling can be triggered by schedules in addition to the conditions typically used for a demand-based approach. At Mission, we codify schedules for auto scaling into infrastructure as code templates, such as those provided by CloudFormation.
In some cases, vertical scaling is preferable to horizontal scaling, and EC2 instances can be modified to alternate instance sizes or classes using the EC2 API. Similarly, EBS instances can be given increased IOPS via snapshotting and restoring to alternate volume types.
When designing your system for a time-based approach, make sure to consider how consistent your usage pattern is, and what the impact of a change in that usage pattern would have upon your system. When employing a time-based approach, AWS encourages you to monitor your usage patterns and periodically adjust your scaling schedules.
Focus Area: Expenditure Awareness
As the member of an executive team, one of the most biggest drivers for effective decision making is clear metrics. Having a deep understanding of the costs and profitability of individual business units, product teams, and systems is critical, but implementing accurate cost attribution can be a challenge. AWS recommends taking a holistic, multi-faceted approach to develop expenditure awareness.
Stakeholders
Having the right stakeholders involved in expenditure discussions ensures better outcomes. AWS recommends involving financial stakeholders such as CFOs or controllers, business unit owners, technical leadership, and any third parties that may be directly involved in influencing infrastructure expenditures.
It is important that financial stakeholders are given the opportunity to deeply understand many of the concepts we’ve discussed today – the cloud consumption model, purchasing options for compute, and AWS’ detailed billing and usage data exports. Finance teams can often struggle at first when navigating the shift from on-premise to on-demand infrastructure, but it has been my experience that once finance teams see the detailed, granular reporting that is possible with cloud infrastructure, they quickly embrace the change.
Business unit owners benefit greatly from involvement in expenditure awareness, as they’re responsible for building sustaining, profitable businesses with viable business models. They need the ability to forecast growth and expenses, and to make critical decisions on purchasing Reserved Instances.
If technical leadership is left out of the conversation, then hidden costs could creep into the picture, and opportunities for efficiency and optimization could be missed, or worse, costs could allocated to the wrong product or business unit.
Visibility and Controls
Once the proper stakeholders have been identified, its time to start gathering data. AWS gives users a huge number of reports and tools for surfacing insights into spend. It all starts with the AWS Billing and Cost Management service, which includes tools for estimation and forecasting, alerting, spend analysis, and Reserved Instance (RI) reporting.
Mission performs Cloud Optimization services for many of our customers, and the RI Utilization Report and RI Coverage Report are a key tools in our optimization tool belt. Between them, you can dive deep into your RI utilization, and look for coverage gaps in your RI spend. You can even set up alerting thresholds for monitoring your RI coverage. For additional billing alerting, you can set up CloudWatch alerts and notifications based upon financial thresholds across a variety of constraints.
AWS provides simple forecasting in the Cost Explorer tool, and you can also define a Budget in the AWS Billing and Console Management service. Budgets can also trigger notifications when you’ve crossed a percentage threshold of your total monthly budget.
If you’re ready to dig deeper, run the Detailed Billing Report with resources and tags along with the Cost and Usage Reports, which give you deep, granular data down to hourly charges and usage for every AWS service. Because the data is so granular, it can be helpful to load it into a tool to help navigate it.
In addition to the reports and tools provided for free by Amazon, there are many third party tools available for digging into your costs, including those from CloudCheckr and Cloud Health Technologies. If you’re having trouble keeping track of costs yourself, consider engaging with an expert partner like Mission: we’ve been helping customers understand and optimize their AWS spend for years.
Cost Attribution
Now that you’ve gathered data, there are two methods to consider for cost attribution: account structuring and tagging. Proper cost attribution will require employing one or both of these techniques.
Account Structuring
AWS gives you the ability to create “child” accounts under a single “parent” account which is used for paying your bill. Using a multiple AWS accounts and linking them together in this way, you can segment your usage into business units, workloads, cost centers, etc. AWS makes it clear that there is not a “one size fits all” answer for how you can structure your accounts.
Once accounts are created for segmentation, they can all be linked up to a master payer account for consolidated billing, while still providing visibility into each individual accounts’ usage.
Tagging
AWS supports pervasive tagging on resources created within your account, including EC2 instances, S3 buckets, and more. By tagging your resources with organizational and business information, you can gain a whole new perspective into your spend. At Mission, we’re frequently engaged to help businesses systematically tag their resources by cost center, application, project, and business unit. Tag data is surfaced in detailed billing and cost allocation reports.
Tagging has benefits above and beyond reporting. Automation can make use of tagging to drive costs down even further. For example, one could tag all EC2 instances that are only necessary during business hours with a special tag, and then create a scheduled Lambda function to list all instance with that tag, and start and stop them each working day.
Entity Lifecycle Tracking
One of the side effects of on-demand infrastructure is that resources can be provisioned with such ease that they can become orphaned or forgotten if not properly tracked. AWS provides services like AWS Config, AWS CloudTrail, and Amazon CloudWatch to inventory and audit your resources. Frequently and continuously auditing your resources is critical to understanding and controlling your costs.
Focus Area: Optimizing Over Time
Continuous improvement is the hallmark of an organization that has fully embraced the agility that cloud can enable. AWS encourages organizations to pursue continuous improvement and optimization with two approaches.
Measure, Monitor, and Improve
AWS outlines a system that you can implement in your organization to drive optimization through measurement. First, they recommend that you establish an official cost optimization function within your organization. This doesn’t necessarily mean that you have to create a new team. Many organizations perform cost optimization in their Cloud Center of Excellence, or they establish a new cross-functional group within the company to provide this function. The purpose of the cost optimization function is to guide technical systems, people, and processes toward controlling and optimizing spend.
AWS then recommends establishing strong goals and metrics for the organization to measure itself against. These goals should of course include costs, but should also surface business output of your systems to quantify the impact of your improvements.
Next, AWS suggests implementing tooling like the Billing and Cost Management Dashboard, Amazon CloudWatch, and AWS Trusted Advisor to measure and monitor your usage.
Finally, your Cost Optimization function can take its learnings, and provide regular reports that show progress toward organizational goals.
Staying Evergreen
AWS innovates at a breakneck pace, introducing hundreds of new features, and dozens of new services each year. As a result, its important that you keep pace by reviewing your architectures on a regular basis to ensure that they say “ever green,” and cost effective.
Engaging with a partner like Mission is perhaps the best way to ensure your business stays on top of the rapid pace of change of AWS. Our team takes great pride in our experience, and we’re constantly learning and adding additional certifications to show our expertise. We perform regular architectural reviews with our customers to make sure that they’re getting the most of their AWS investment.
Conclusion
I hope this deep dive into cost optimization has given you the tools necessary to optimize your AWS spend. Go forth and optimize!
As an AWS Well-Architected Review Launch Partner, Mission processes assurance for your AWS infrastructure, processing compliance checks across the five key pillars. Reach out to Mission now to schedule a Well-Architected Review.
FAQ
- How can organizations track and manage the costs associated with underutilized resources specifically, and what tools does AWS offer for this purpose?
For tracking and managing costs associated with underutilized resources, AWS offers several tools such as AWS Cost Explorer, AWS Budgets, and Trusted Advisor. These tools help organizations identify underutilized resources and provide recommendations for resizing or terminating them to optimize costs. AWS also have Premier Partners, such as Mission Cloud, that can support organizations in their AWS optimization strategy.
- What are the challenges in implementing a cost-aware culture within an organization, and how can leaders overcome these challenges?
Implementing a cost-aware culture poses challenges such as resistance to change and a lack of understanding of cloud cost management principles. Overcoming these requires clear communication of the financial benefits, training for relevant stakeholders, and establishing policies that encourage cost-effective resource usage.
- Can you provide examples of real-world savings achieved by organizations after applying the best practices from the Cost Optimization Pillar?
- Examples of real-world savings from applying Cost Optimization Pillar best practices include organizations reducing their monthly AWS bills by optimizing their use of resources, such as by selecting more cost-effective service options, automating resource shutdown during off-peak hours, and leveraging reserved instances or savings plans for predictable workloads.