
Complicated Kubernetes Clockwork
If you’re here you probably don’t need to be sold on the benefits of containers. They are a great way to achieve a wide set of efficiencies related to scaling, performance, and cost.
This post will focus specifically on Kubernetes, an open-source system for automating application deployment, scaling, and management. When I first started diving in and trying to learn Kubernetes, I was overwhelmed by all the inner workings, services and functions that are required to get Kubernetes clusters to run.
The more I understood, the more impressed I was: Kubernetes is self-healing, so if a gear breaks that component will be killed off and replaced (if set up properly.) Let’s now delve further into the business use case for containers and Kubernetes before discussing how to get started and up and running quickly.
Business Case for Containers and Kubernetes
If you’re no longer running hardware, you’ve moved your VMs into the cloud, and you don’t want applications sitting idle and wasting compute hours, you need to be able to make changes faster and you need multiple layers of resiliency. Becoming cloud-native is a way to leverage these efficiencies and gains.
The Path to Becoming Cloud-Native
So, what is the best way to becoming cloud-native? Orchestrating containers using Kubernetes is the short answer. But I always recommend not forcing adoption of technologies. Sometimes monolith applications need to be carved apart slowly and carefully into microservices in order to gain those efficiencies over time.
Kubernetes Services and Components
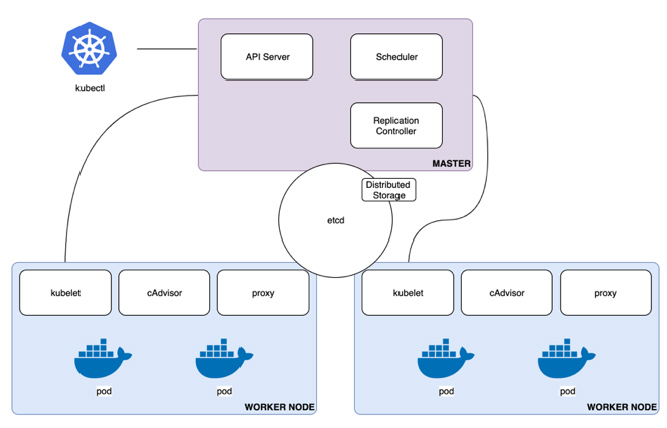
Now, let’s dig into the Kubernetes components. This diagram depicts just some of the controllers and functions.
The API is is how the kubectl interfaces with the services, and the SED service is the name value store used by everything. The schedulers and controllers decide what is running and where to put objects. The overlay network is the network space internal to the cluster. Worker nodes or where your containers run. The cubelet is a container that runs on all of the worker nodes. The cAdvisor and proxy are some example add-ons that expose services (the proxy) and gather metrics (the cAdvisor). Some other add-ons that we often use are fluent D for logging and heapster for additional metrics but we’ll talk about some of those later. Last thing before moving on, I really like talking about this slide because we no longer need to know or worry about the top half of this diagram with the introduction of Amazon Elastic Container Service for Kubernetes (Amazon EKS).
Introducing Amazon EKS
Amazon EKS makes it easy to deploy, manage and scale containerized applications using Kubernetes and you no longer need to worry about the inner workings of the services required to manage and scale the cluster. You can just create that cluster control plane in the console or with a command line and EKS workers that will allow you to start deploying containers.
Creating the Cluster
Creating an EKS cluster is relatively straightforward compared to some of the other container orchestration services I’ve tried to use in the past. It’s four quick steps and we do the first three steps of this with Terraform that include:
- Create IAM roles (and VPC)
- Create EKS cluster
- Launch Worker Nodes autoscaling group
- Deploy the config map to link the Workers to the cluster
Now, there’s an even easier way to create a cluster, and it’s with the command line EKSCTL, which can create the cluster with one quick command line.
The kubectl Command
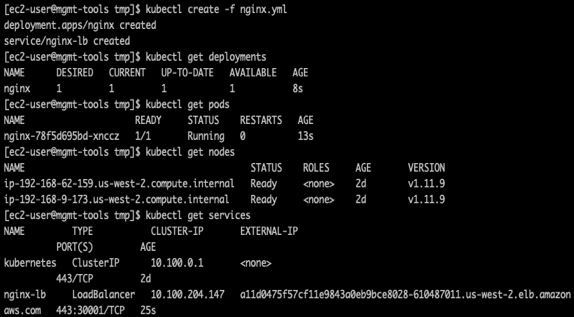
The kubectl command controls and sees everything in your cluster, and so when I finally got to start playing with the kubectl command, that was my aha moment. That is where all of the fun happens, and the certified Kubernetes administrator exam is all about this command line. As you can see in this shell, I created objects using a YAML file that set up a deployment of containers or pod which, is a set of containers and I’ll talk about the contents of that yaml in the next slide.
You can update objects, patch, edit, scale SSH or interact with pods nodes and clusters. Make sure to set up autocomplete in your shell as it makes things a lot easier.
The Manifest
Now into that nginx.yml file i used to create the objects. This is a relatively simple set up, with an nginx web service and a load balancer.
First there is the KIND of object to create: Since we need to launch image first, We’re doing a Deployment here for stateless containers. There are some Other types of container image creations. You could use the less common, StatefulSets when you need persistent volumes. Or DaemonSets which only run one pod on every worker node. Logging and Monitoring are common examples of DaemonSets. Or “Jobs” will run a set of pods until completion and report success or failure. There is also CronJobs type.
Then there is the Namespace: this is Intended for use in environments with many users or projects within a cluster for organization mainly. Most often the default namespace is used, which is called, “default”. I’ve found Labels to be more useful, as they can be modified. Labels are like a release type(canary or stable), the environment (dev/prod), or the tier or customer name. They can also be used for node affinity, which ties certain containers to run on certain EC2 worker nodes.
Then there is the Image specification: This is an ECR Repo ARN. Some items missing commonly used in a deployment YAML block.
- imagepullpolicy. after the image line, to dictate whether or not to always pull latest when applying this YAML.
- Environment variables. for the container’s connection strings for example.
- liveness readiness. which are extra validations you can monitor the functionality of your container and kubernetes will cycle the pod if failed.
Notice the “Replicas” line in the Spec. It’s only 1. That’s not right. This is a web service and we need it to be redundant. We can change that later with another kubectl command to create an autoscaling group of containers or horizontal pod HPA.
Options for Scaling and Monitoring Containers in Kubernetes
So now we’ll talk about some scaling options. I mentioned that HPA or horizontal pod autoscaler that triggers on CPU by default but it can be triggered by external resources, like a Queue.
If you’ve built the worker nodes with EKS CTL or the example CloudFormation template, you’ll need to create an auto scaling trigger to scale up and down those EC2 worker nodes specific to your workload bottlenecks, like memory or latency.
The metrics server can do more internal monitoring and triggering for HPA’s
The dashboard is a handy tool that you need to install and configure with a deployment yaml you can download. Prometheus is often used for better visibility and monitoring than the dashboard provides.
CloudWatch metrics for EKS are not available out of the box, there are some steps to take to see networking metrics. with the CNI metrics helper
Streaming logs can be done simply with FluentD into your favorite log aggregator.
Container-based Continuous Integration Strategies
Now we’ll dive into some continuous integration strategies. You can automate deployments with the kubectl command, with HPA’s and rolling updates. But if you want to have more flexibility, Helm is the command line and Tiller is the service that runs inside Kubernetes. When you leverage Helm and Tiller, you don’t need to hard code a bunch of stuff into yaml files. Helm allows for that parameterization and can manage the deployments.
Canary Deployments
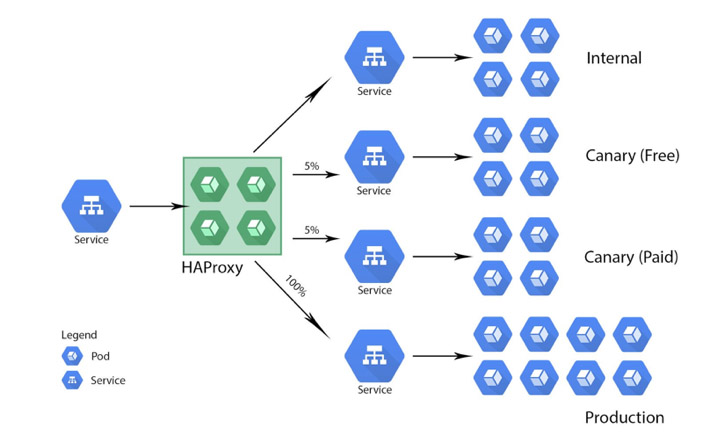
Canary deployments are a strategy to roll out releases to a subset of users or servers to test performance before releasing to a larger audience. In order to do this, you can create a new deployment yaml with the same app label but additional canary labels to test new functionality, without bringing down your existing production. As long as you use the same app label, the load balancer will send a percentage of traffic to those new canary pods. Once the canary has been validated as working, you can roll the new version in your standard deployment out and kill the canary.
Blue-Green Deployments
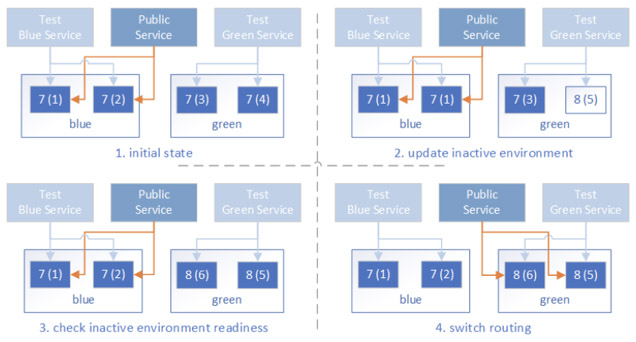
Blue/Green deployments is a technique that reduces downtime by running two identical production environments called Blue and Green. At any one time, only one of the environments is live. The other one is used for deployment and testing.
With Blue/Green or A/B testing you can use a second load balancer to test the new functionality and use DNS weighted alias records to distribute traffic and slowly move onto the new app version. The diagram depicts the initial state with the public service pointing to the blue side and version 7. Then we do a rolling update on the green side to version 8. We Validate version 8 with smoke and load tests, then cutover.
This requires additional deployment yaml and load balancer service, but can be setup in the same cluster. LaunchDarkly is a third party paid tool I came across recently that helps in this area for configuration and reporting.
Rolling Deployments
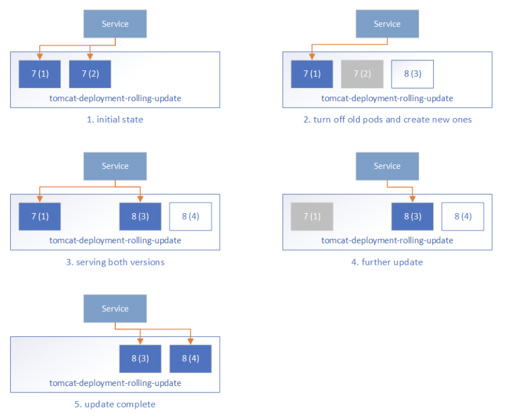
A rolling deployment is a software release strategy that staggers deployment across multiple phases. This is probably the most common scenario where containers are replaced one at a time, ultimately eliminating downtime with single kubectl or helm command.
Security Strategies for Kubernetes and Containers
Now for some security strategies. We strongly recommend using AWS security tools. Especially CloudTrail. The API access from kubectl to EKS is authenticated with the kubeconfig, and IAM service roles. Make sure CloudTrail is on globally so EKS activity is logged. CloudTrail, Config, GuardDuty, WAF, Shield, Macie and more with the AWS Security Hub are all security governance tools available to you in your AWS account waiting to be turned on. Additionally, you should implement a logging DaemonSet to gain additional insights.
How Mission Can Help
Mission can help you build a strategic roadmap that addresses how to leverage containers and container orchestration in order to meet your organization’s objectives. Schedule a free 60-minute consultation with one of our Solutions Architects here.



