
Although machine learning (ML) is increasingly popular, training and deploying ML models into production is challenging, even for experienced development teams. According to Capgemini’s State of AI Survey, a shocking 72 percent of organizations that began AI pilots before 2019 have yet to deploy a single app in production, proving how tough it is for enterprises to scale AI projects.
Amazon aims to change that with SageMaker, a fully-managed ML service that simplifies the process of building, training, and deploying ML models using an assortment of ML frameworks. By providing modular features, SageMaker makes the ML process as straightforward as possible. Developers no longer worry about the intricacies involved in the ML operations process, instead focusing on performing core ML experiments and generating ROI by quickly deploying models in production-ready environments.
Let’s examine some best practices to build secure and performant solutions using SageMaker. These practices include:
- Building and training models using SageMaker Studio.
- Choose the correct size for your notebook instances.
- Decide whether you need endpoints or batch transforms.
- Size your inference endpoints correctly.
Use SageMaker Studio
Consider using SageMaker Studio whenever possible. As a web-based, fully integrated development environment (IDE) for ML, SageMaker Studio lets you do everything in one place and provides you with all that you need to create a production-ready model. SageMaker is based on open-source JupyterLab, where you can create notebooks, write code in python, and build, train, and deploy ML models. It allows you to monitor model performance and compare results within a single interface.
A unique feature of SageMaker Studio is its ability to launch shells and notebooks in isolated environments. The Launcher page, which has over 150 open-source models and 15 pre-built solutions, enables you to build your model using Amazon SageMaker images, which have the most upto date versions of the Amazon python SDK. Additionally, you can use custom-built algorithms written in one of the many supported ML frameworks, like Google TensorFlow, PyTorch, and MXNet. Just note that you can host these algorithms only if you have encapsulated them in a SageMaker-compatible Docker container.
Until recently, you were only able to use pre-built images with the SageMaker Studio environment. With the launch of lifecycle configurations, you can directly attach approved customizations to the SageMaker Studio environment. SageMaker Studio provides security hardening capabilities using encryption in motion, encryption at rest, and virtual private cloud (VPC) support to handle the security pitfalls of customizable environments.
SageMaker Studio has several automation tools to accelerate the ML process and provide greater visibility and control over the various steps required to build production-ready models. These are just some of the available tools:
- AWS Autopilot automatically builds and trains ML models while providing you with complete visibility into model creation.
- Data Wrangler is a quick way to prepare data. It has many common data cleaning techniques that can reduce the time for data cleansing from weeks to minutes.
- Debugger monitors your models for bottlenecks.
- Edge Manager extends ML monitoring to edge devices.
- Ground Truth accelerates data labeling and lets you create high-quality training samples.
- Model Monitor monitors ML models and notifies you when it detects deviations.
- Pipelines automate ML workflows, enabling you to scale ML across your organization.
- SageMaker Project is an AWS Service Catalog–provisioned product used to create an end-to-end ML solution
Choose Correctly Between Studio Notebook and Notebook Instances
SageMaker provides two options to launch a notebook. You can launch notebook instances and Studio notebooks. Although they might appear similar, they are notably different. With notebook instances, you have the flexibility to create your notebook according to your specifications. Compared to Studio notebooks, notebook instances are more hands-on and involve a steep learning curve.
When you launch a notebook instance, you must manually set up an elastic cloud compute (EC2) instance, select from the built-in algorithms or import your algorithm, specify the data’s location in Amazon S3, and choose the preferred instance type. In contrast, Studio notebooks are one-click Jupyter notebooks equipped with pre-built images that can spin-up five to ten times faster than notebook instances.
Since you can access Studio notebooks from within SageMaker Studio, you can build, train, and monitor your model without leaving Studio. Furthermore, the computing resources in SageMaker Studio are highly elastic, meaning they can scale to meet changing needs without the need for manual capacity planning. So, you can switch to a compute with more GPU, more CPU, and more memory with the click of a button for a seamless, developer-friendly experience.
When you select a notebook in SageMaker Studio, its status is InService. Once the status is InService, AWS starts charging you, regardless of if you use it. So, ensure you turn it off or delete your notebook instance when not in use. However, you must understand that only files and data saved within the /home/ec2-user/Sagemaker directory are safe. SageMaker Studio overwrites any data you save outside this directory when you stop the instance and restart it.
On the other hand, Studio notebooks enable persistent storage, so you can view and share notebooks even when you shut down the instances where the notebooks are running. SageMaker Studio also makes it easy to share a notebook — users can generate a sharing link for their colleagues to view and run a notebook. Sharing isn’t quite as easy using a notebook instance, though.
Again, users can directly sign into SageMaker Studio using single sign-on (SSO) without going through the AWS console. This SSO approach is helpful for ML practitioners and developers who want to access their ML IDE without knowing about other parts of AWS. Using notebook instances in this way requires significantly more knowledge.
Decide Whether You Need Endpoints or Batch Transform
Once you’ve trained a model, the next step is to perform inferences so others can derive real value from your model. One approach is to create a batch transform job to get predictions on the entire dataset. Otherwise, you can create HTTPS API endpoints for performing predictions one at a time in real-time. While endpoints are easy to spin up and great at providing real-time predictions, you need batch transform if your goal is to serve predictions on a schedule.
Batch transform is a highly efficient way to perform inferences on large sample sets when you don't need to do them in real-time and where latency is not an issue. Batch transform is preferable when:
- You need inferences for large datasets
- You don't need persistent endpoints
- You don't need low latency
Ultimately, choosing one over the other depends on how and when you need your inferences. If you need inferences individually and upon request, opt for endpoints. Otherwise, batch transform is the way to go.
Size Endpoints Correctly
A SageMaker endpoint uses HTTPS requests for users to make real-time inferences through REST API calls. Unfortunately, prediction instances run constantly, and you cannot terminate them automatically. This situation can amass enormous costs. It is no wonder that most deep learning applications spend up to 90 percent of their computing costs on making predictions or inferences. Therefore, rightsizing ML inference infrastructure is necessary for optimizing your hosting costs.
If you plan to use endpoints, ensure you size them correctly to have the required capacity without overspending. Load testing the model helps you find the right fleet size and instance type and ensures you avoid over-provisioning. Keep testing to determine how the model responds to different load conditions. Also, auto-scale your endpoints in response to changing workloads. That approach enables you to arrive at the most cost-effective solution.
Monitoring Endpoints Using CloudWatch
Track the load on EC2 endpoints backing your instances. If they’re not receiving much traffic, you might be able to handle all of your endpoint’s needs with a smaller, less powerful instance.
Amazon CloudWatch is a metric repository that gathers data and analyzes metrics in real time. The CloudWatch interface displays all the data in a graph format. You can also build custom dashboards for particular metrics depending on your specific needs.
In addition, CloudWatch enables you to set alarms to notify you whenever your endpoint use exceeds a certain threshold. CloudWatch enables you to study your use and optimize your instances’ performance by providing complete visibility into your running instances.
Using SageMaker Multi-Model Endpoints
Today, it is common for businesses to deploy multiple models for individual use cases, but deploying so many models dramatically raises your costs. SageMaker multi-model endpoints are a scalable and economical way to deploy multiple models. These multi-model endpoints use a shared container to lower deployment costs and optimize endpoint use.
Apart from multi-model endpoints, several other SageMaker metrics are available in CloudWatch to help you arrive at the correct decision:
- SageMaker Endpoint Invocation Metrics
- SageMaker Feature Store Metrics
- SageMaker Jobs and Endpoint Metrics
- SageMaker Ground Truth Metrics
- SageMaker Pipelines Metrics
Optimizing Costs
Identifying idle endpoints and stopping them from running improves cost optimization. Use CloudWatch Events and Lambda functions to detect idle resources and take corrective measures.
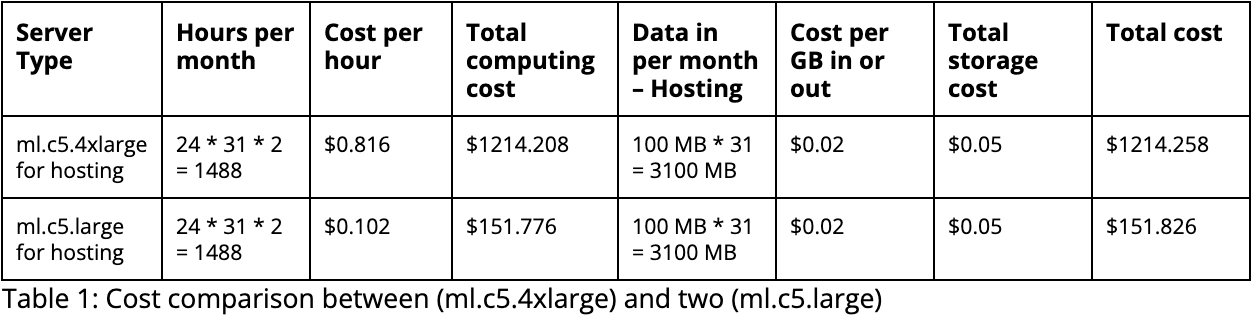
As shown below, Table 1 demonstrates the cost comparison between deploying two large instances (ml.c5.4xlarge) and two medium instances (ml.c5.large). Assuming the instances run 24 hours a day for a month, the table shows that the cost of running the large instances is more than 8 times of the medium instances.
Conclusion
If you want to execute an ML project end-to-end, Amazon SageMaker is for you. By abstracting the infrastructure needed to accomplish an ML task, SageMaker removes the heavy lifting required to manage ML project complexities and provides you with an easy and effective way to develop ML models at scale.
As an AWS consulting partner, Mission can guide you on using SageMaker effectively in your organization for your machine learning applications. Download our guide on How to Build a Strong Foundation in SageMaker, or contact us to learn more.
FAQ
How does SageMaker ensure data security and compliance for highly regulated industries, such as healthcare and finance?
Amazon SageMaker is designed with built-in features to address the stringent security and compliance demands of sectors such as healthcare and finance. It leverages AWS’s robust infrastructure to provide end-to-end encryption, both in transit and at rest, ensuring that data is protected at every stage of the machine-learning process. For healthcare, SageMaker supports HIPAA compliance, offering tools and configurations that safeguard patient data. Similarly, SageMaker adheres to PCI DSS standards for the financial industry, ensuring that sensitive financial information is handled securely. SageMaker also offers detailed access controls and logging capabilities, enabling organizations to monitor and manage who has access to their data and models, further bolstering security and compliance efforts.
What are the cost-optimization strategies specific to SageMaker?
Cost optimization in Amazon SageMaker can be achieved through several strategies designed to balance performance with expenses. One effective approach is utilizing SageMaker's instance selection feature to choose the most cost-effective compute resources for your machine learning workloads. Additionally, SageMaker's Managed Spot Training allows users to take advantage of unused EC2 instances at a fraction of the cost, which can significantly reduce training expenses. Another strategy involves optimizing the use of SageMaker's endpoints for model inference. By auto-scaling these endpoints based on demand, users can ensure they are only paying for the computing capacity they need. Finally, employing SageMaker's model monitoring tools to track the efficiency and accuracy of models over time can help identify when retraining is necessary, preventing unnecessary computational spending.
Can SageMaker integrate with other AWS services for a more comprehensive data analytics and machine learning ecosystem?
Amazon SageMaker seamlessly integrates with a wide range of AWS services to create a comprehensive and cohesive machine learning and data analytics ecosystem. This integration facilitates a smoother workflow from data collection and preparation to model training, deployment, and monitoring. For instance, SageMaker can directly interact with Amazon S3 for storing and retrieving datasets, AWS Glue for data preparation and ETL jobs, and Amazon Athena for querying data directly from S3 using SQL. Additionally, it works hand-in-hand with AWS Lambda for automating workflows and Amazon QuickSight for creating data visualizations. These integrations empower developers and data scientists to construct more efficient, scalable, and powerful machine learning solutions within the AWS cloud environment, leveraging each service's strengths to enhance their machine learning projects.
Authors Caitlin Berger, Na Yu, and Ryan Ries



