
Generative AI utilizing large language models (LLMs) is transforming people’s daily life and work. LLMs are able to improve the efficiency of communications between humans and machines. LLMs also improve people’s productivity with content creation, coding, summarization, and being a host of other applications.
However, there are a few issues when using pre-trained LLMs straight out-of-the-box. One common issue is hallucination due to the fact that generative AI makes a prediction based on underlying mathematical equations. Hallucination refers to a phenomenon where a LLM generates text that appears coherent and contextually relevant, but is actually incorrect or inaccurate. The second issue is that LLMs were trained on past information. For questions on information that is fresh and frequently changed, a LLM cannot answer correctly.
A reference architecture and its implementation of Retrieval Augmented Generation (RAG) are available in this AWS blog. The blog uses Amazon Kendra web crawler to crawl websites and creates a Kendra index as the knowledge database. LLMs used in this architecture can be variant.
In this post, you will learn to use Amazon Kendra to index and search PDF files in your ecosystem. You will also learn to launch a LLM available as a SageMaker JumpStart model (a pre-trained model containerized by AWS). You will then use an Amazon SageMaker Studio notebook to launch a Streamlit web application for querying and getting answers from the PDF files in Kendra. We will present detailed configuration steps for Kendra and Sagemaker.
Solution Architecture
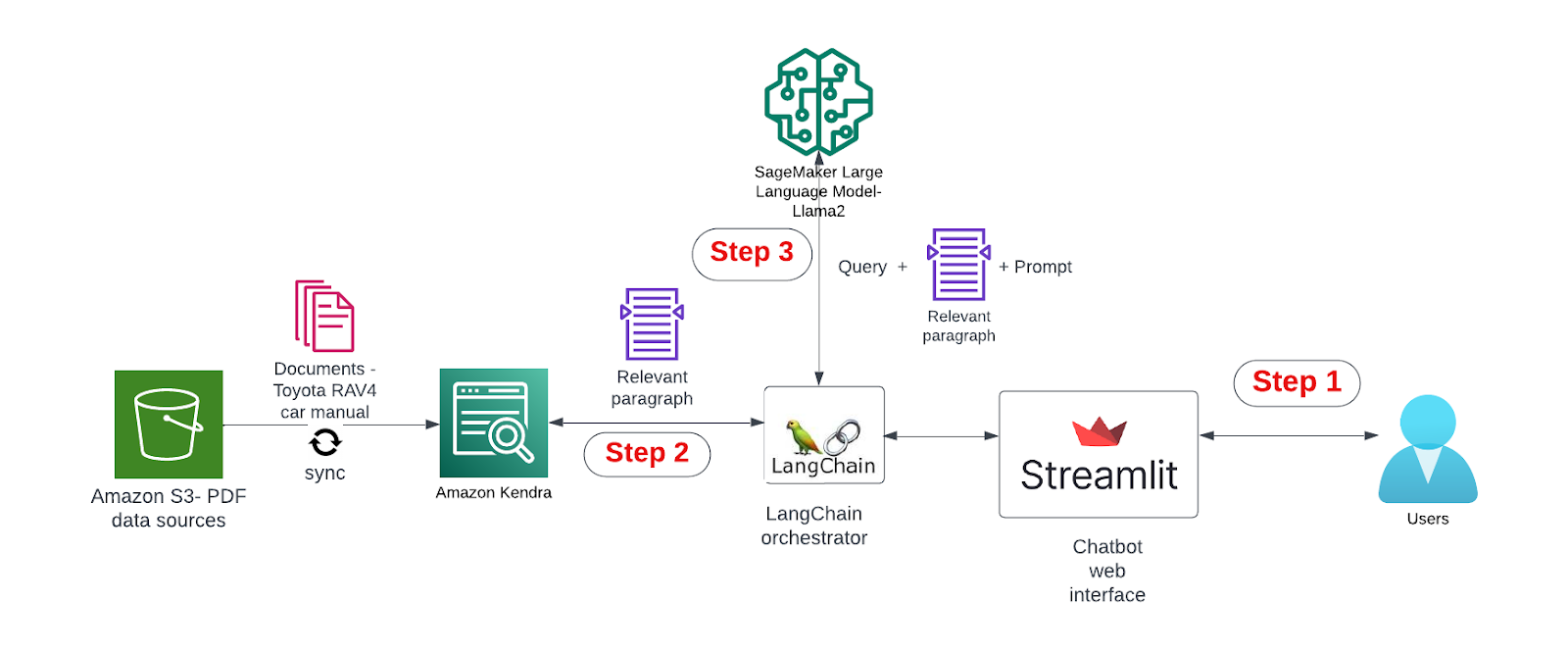
Below is a diagram that shows the overall workflow. Raw data is stored in the S3 bucket and we use a car manual PDF in this blog for illustration purposes. Amazon Kendra is used to index the data sources and serves as a knowledge database. We use the Llama2 model as the LLM for text generation. Llama2 is deployed as a SageMaker endpoint by SageMaker JumpStart.
There are three main steps in the workflow of RAG:
1) Users input requests through the Chatbot web interface built by Streamlit.
2) LangChain is used as an agent framework to orchestrate the different components; Once a request comes in, LangChain sends a search query to Kendra to retrieve the context that is relevant to the user request.
3) LangChain then sends a prompt that includes the user request and the relevant context to a LLM. The results from the LLM are sent back to users via the Chatbot web interface.
Solution Walkthrough
This section walks you through the steps to set up the RAG solution.
Index the data sources using Amazon Kendra
-
Log into your AWS account and search for Kendra.
-
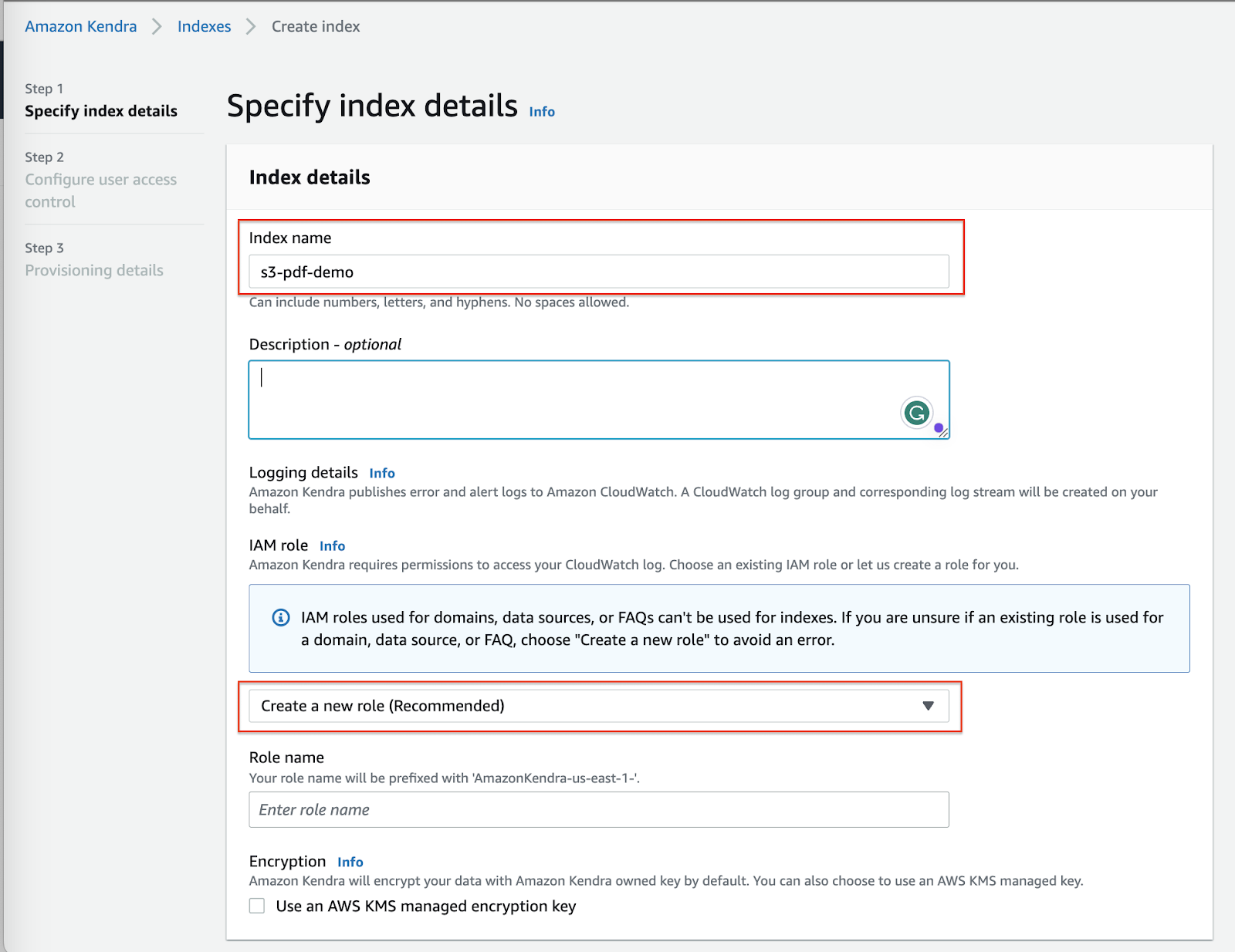
On the Kendra console, click Create an Index.
-
Give an Index name and Create a new role (recommended), as shown below.
- Keep everything else as default and create the index. It can take a few minutes to create the index.
- Once the index is created. Click add data sources.
- Choose Amazon S3 connector.
- Specify the data source name and choose the language of the source documents.
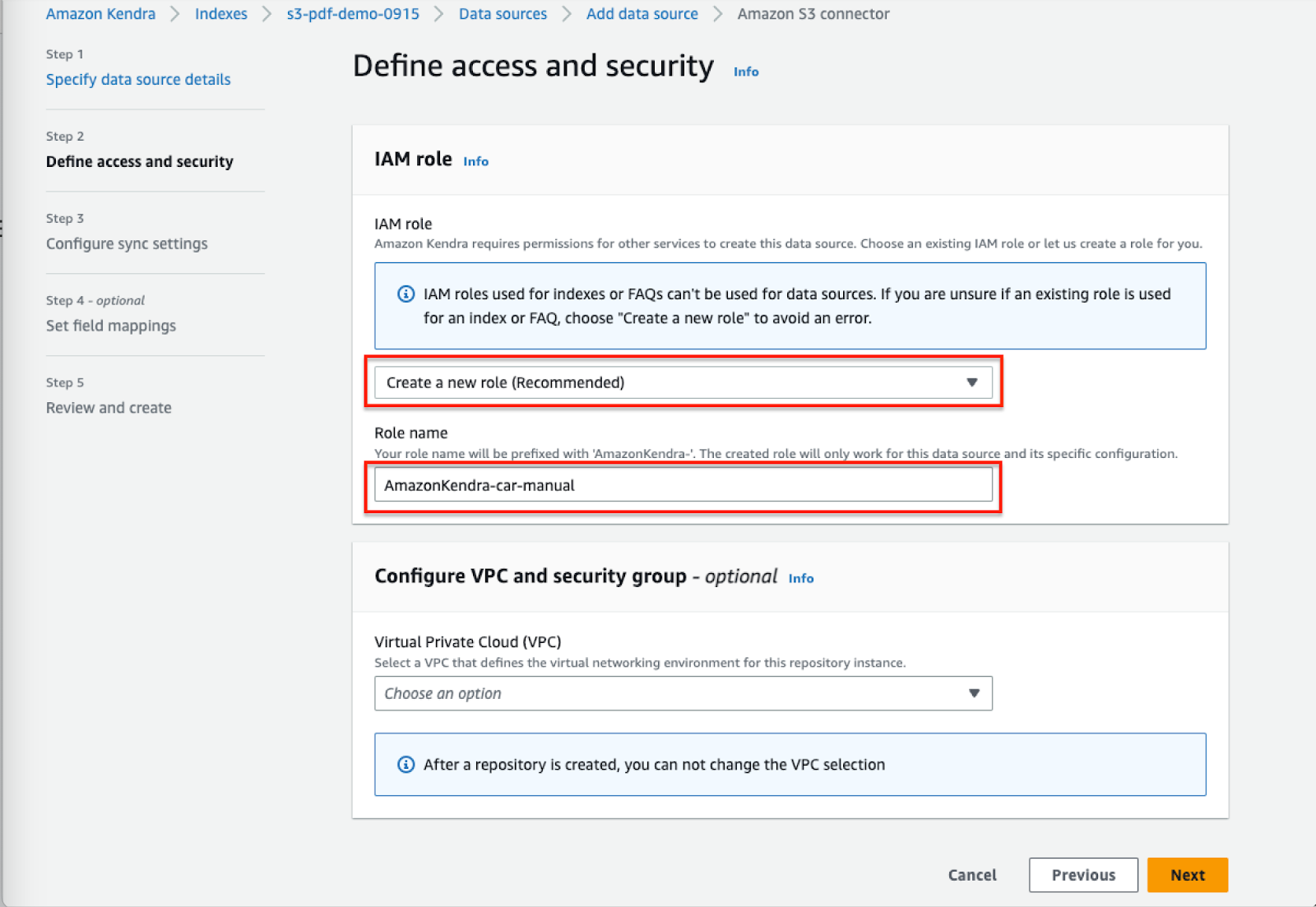
- Choose to create a new role, give the role a new name and leave everything else as default.
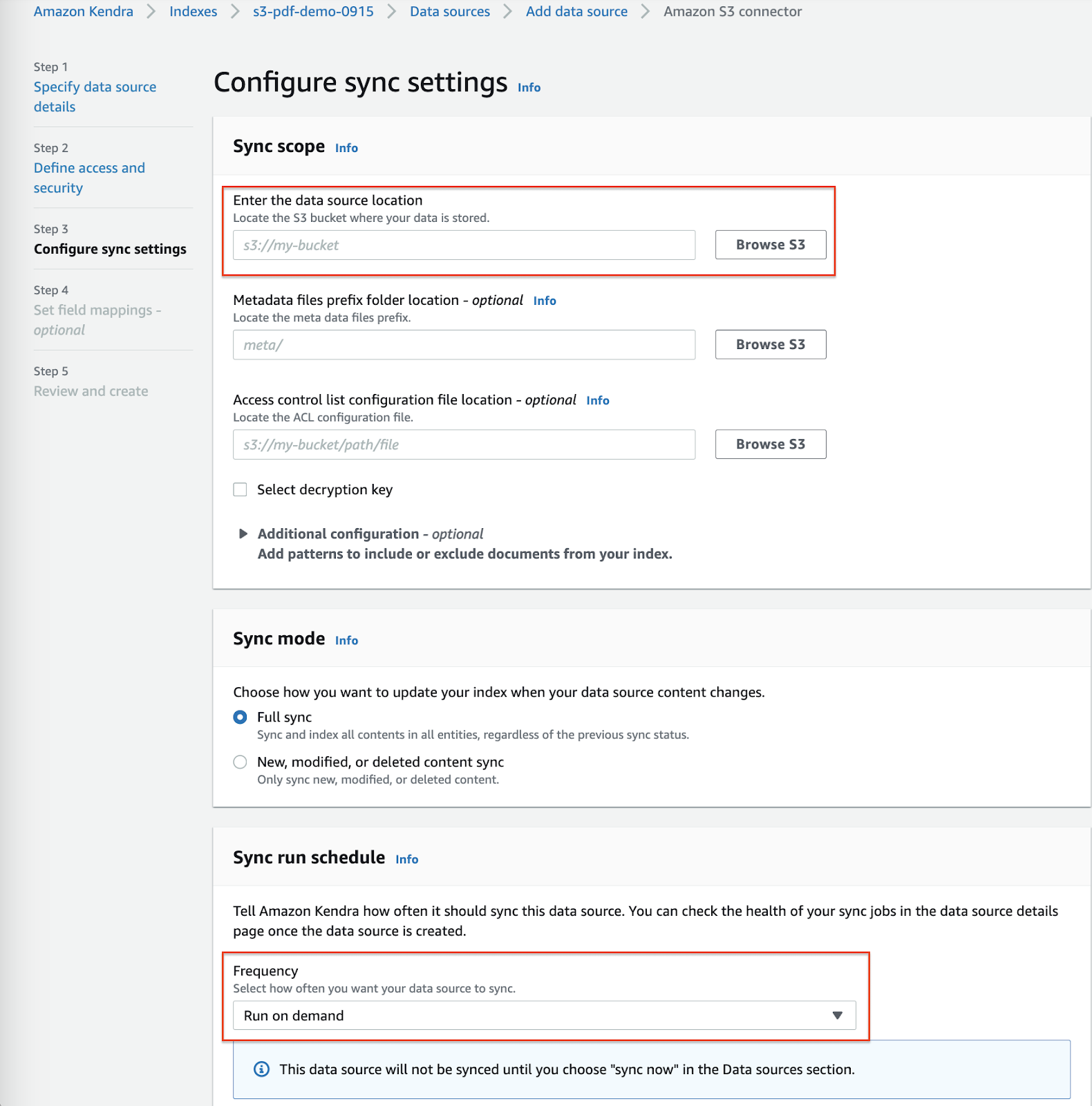
- Choose the S3 location where the PDF is located and choose the Run on demand schedule. Leave everything else as default.
-
Go to the next page, leave everything else as default, and click add data source at the end.
-
Click the Sync now button on the Data sources page. It can take minutes to hours to finish the sync depending on the size of the documents. As a reference, for the car manual that has around 400 pages, it takes about 15 minutes to finish.



Deploy a LLM from Amazon SageMaker Jumpstart
-
Go to SageMaker Studio.
-
Go to SageMaker Jumpstart, click “Models, notebooks, solutions”, and search for “Llama-2-7b-chat” model.
-
Select an EC2 instance type from the SageMaker hosting instance dropdown list. Note that you might need to request service quota increase if the selected EC2 instance is not available in your AWS account. Then give an Endpoint name that you would use later and click deploy. It might take 15-20 minutes to deploy the endpoint.
- Once the endpoint deployment is finished, you should see the endpoint status showing in service.



Launch the Chatbot application
1. Launch the Chatbot application on SageMaker Studio
-
Setup your SageMaker Studio working environment and launch SageMaker Studio.
-
On SageMaker Studio, select File -> New -> Terminal to create a new Terminal.
-
On the terminal, run the commands below, following the instructions in the Github Repo. The commands clone the repo and install the prerequisites, including LangChain, boto3 and Streamlit.
git clone https://github.com/aws-samples/amazon-kendra-langchain-extensions.git
cd amazon-kendra-langchain-extensions
cd kendra_retriever_samples
pip install -r requirements.txt - Export the environment variables for the region name, the Amazon Kendra index number, and the SageMaker endpoint name that are used by the script kendra_chat_llama_2.py.
export AWS_REGION=<YOUR-AWS-REGION>
export KENDRA_INDEX_ID=<YOUR-KENDRA-INDEX-ID>
export LLAMA_2_ENDPOINT=<YOUR-SAGEMAKER-ENDPOINT-FOR-LLAMA2> - To launch the Chatbot, run the command below.
streamlit run app.py llama2
When the application runs successfully, you will see an output similar to the one shown below. Find the port number in the output, where the port number is typically 8501.
sagemaker-user@studio$ streamlit run app.py llama2
Collecting usage statistics. To deactivate, set browser.gatherUsageStats to False.
You can now view your Streamlit app in your browser.
Network URL: http://169.255.255.2:8501
External URL: http://35.170.135.114:8501
- Copy the URL of your SageMaker studio and modify the URL using the port number as below. Enter this modified URL to a new browser, which brings up the Chatbot web interface.
The original SageMaker studio URL: https://XXXXXXXXX.studio.us-east-1.sagemaker.aws/jupyter/default/lab
Modified URL: https://XXXXXXXXX.studio.us-east-1.sagemaker.aws/jupyter/default/proxy/8501/
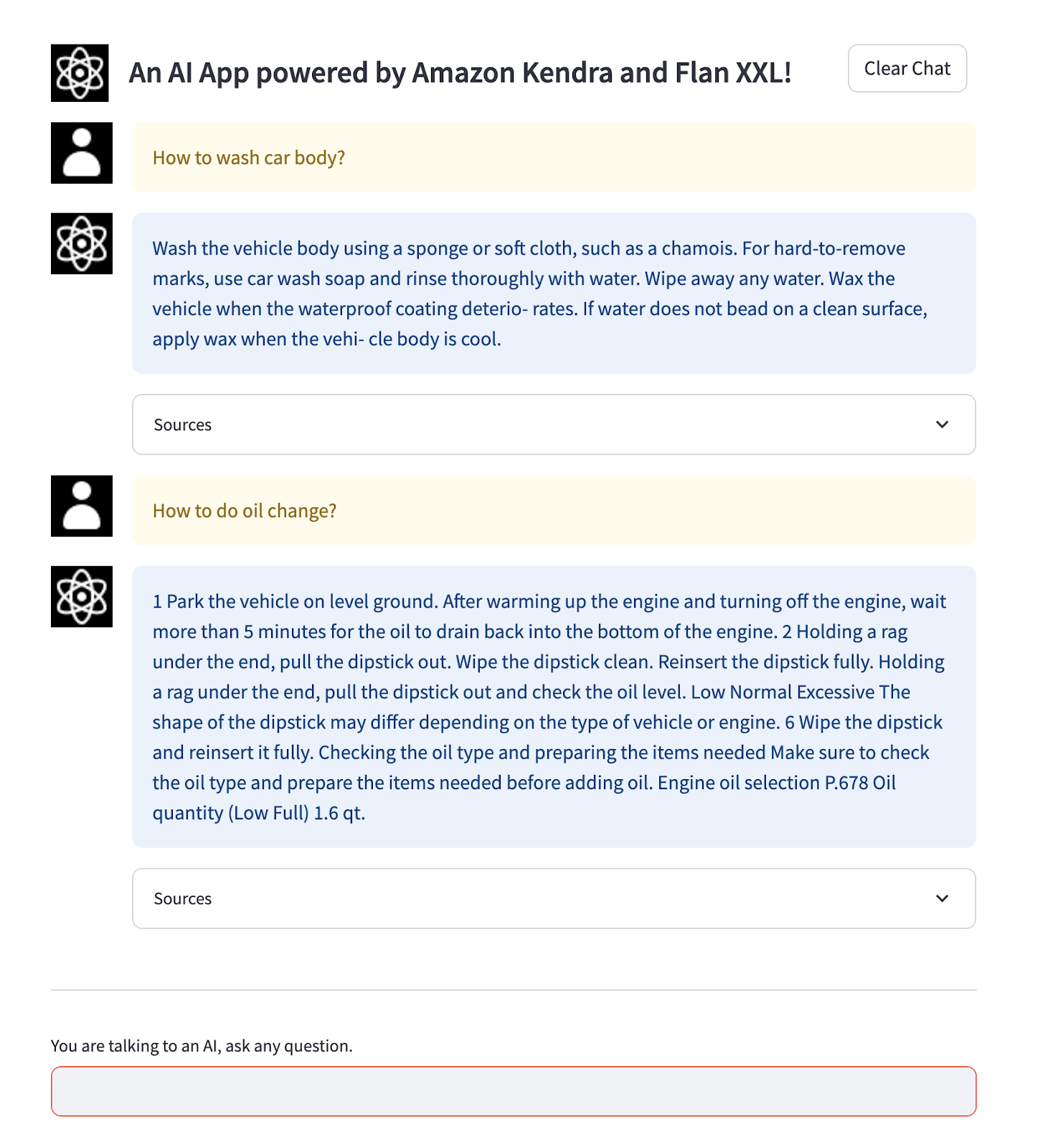
Below shows two testing questions and answers returned by the RAG solution. By clicking the Sources button, it shows the data sources, such as the S3 location of the PDF files.
2. Launch the Chatbot application on EC2 instances
You can also run the Chatbot application on an EC2 instance. For doing this, all the steps remain the same, except in the Step 6. Instead of modifying the URL to access the Chatbot web interface, you can directly click the output URL that contains the port number. This link shows how to set up an EC2 instance. Make sure that the region of the EC2 instance is the same as where the SageMaker endpoint and Kendra are launched.
Clean up resources
Do remember to delete the Kendra index and the SageMaker endpoint to stop charging costs.
Conclusion
In this blog, we show the step-by-step instructions to set up a RAG solution as a proof of concept (POC). The RAG solution includes three major components: a knowledge database for context search, LangChain, and a LLM for text generation. We use Amazon Kendra as the knowledge database. With Kendra, you do not need to deal with the complexity of chunking management and embeddings, and you can connect to a wide set of data sources, such as Amazon S3, Confluence, Slack, Salesforce, etc. Based on your specific use case, there are a variety of knowledge databases to choose from. For example, this RAG solution allows you to optionally use Amazon Aurora Serverless with pgvector and Amazon OpenSearch. For LangChain, there are also other alternatives, such as Semantic Kernel. For production level Chatbot application development, latency would be a crucial factor to optimize. Methods to reduce latency include optimizing the inference EC2 instance, reducing the model size, for example, by using quantization, and utilizing high performance computing, such as Ray.
This blog illustrates how easy it is to set up and test out a Gen AI Chatbot, but for production level systems there are a variety of considerations that need to be taken into account. Mission Cloud is a premier AWS consulting partner that you can utilize to build out a production level system after you have proven the ROI based on this POC-based Gen AI Chatbot.
FAQ
How does chatbots handle ambiguous or contextually complex questions where the answer might not be straightforward or requires interpretation from multiple sources?
Chatbots, designed using LangChain, Amazon Kendra, and Large Language Models (LLMs), are equipped to manage ambiguous or contextually complex queries through their advanced natural language understanding capabilities. The integration of these technologies enables the chatbot to analyze and interpret the nuances of human language, drawing from a vast repository of knowledge and information contained within the documents it has access to. When faced with complex questions, the system utilizes LangChain to orchestrate the process, Amazon Kendra for searching and extracting relevant information from a corpus of documents, and LLMs to synthesize and generate coherent, contextually appropriate responses. This combination ensures that even when questions lack clarity or require deep interpretation, the chatbot can provide accurate, informed answers by considering multiple sources and perspectives, thereby mimicking a more nuanced human-like understanding.
What are the security measures implemented to protect sensitive data in PDF documents when using this chatbot solution, especially considering the integration of external services like Amazon Kendra and SageMaker?
In terms of security, especially when handling sensitive data contained within PDF documents, the chatbot solution strongly emphasizes implementing robust security measures. The integration with Amazon Kendra and SageMaker benefits from AWS's comprehensive security framework, including encryption in transit and at rest, identity and access management, and network security features. Additionally, Amazon Kendra provides fine-grained access control to ensure that only authorized queries are processed and sensitive information is securely handled. Furthermore, developers can implement additional security layers, such as user authentication, access controls, and logging, to monitor and protect against unauthorized access to sensitive information. These measures collectively ensure that the chatbot solution adheres to strict data protection standards, safeguarding against potential breaches and ensuring compliance with regulatory requirements.
Can this chatbot framework be adapted to work with other documents or data sources beyond PDF files, such as web pages, databases, or proprietary document formats?
The flexibility of the chatbot framework, which leverages LangChain, Amazon Kendra, and LLMs, extends beyond the processing of PDF documents. This architecture is inherently adaptable to various types of documents and data sources, including but not limited to web pages, databases, or proprietary document formats. The key lies in Amazon Kendra's ability to index and search across diverse content repositories, whether hosted on AWS or elsewhere. By configuring the data source settings within Amazon Kendra, developers can tailor the chatbot to access and interpret information from virtually any structured or unstructured data source. This adaptability makes the chatbot solution highly versatile and capable of serving various applications across different industries and use cases, from customer support and enterprise knowledge management to educational tools and beyond.



