
Amazon SageMaker Series - Article 2
We are authoring a series of articles to feature the end-to-end process of data preparation to model training, to model deployment, to pipeline building and monitoring using the Amazon SageMaker Pipeline. This second article of the Amazon SageMaker series focuses on how to use Amazon SageMaker Inference Recommender to help choose the optimal instance for endpoint deployment.
As a data scientist, after a long time spent on model training and development, you are finally ready to deploy your model to a SageMaker endpoint. However, you may not know what type of instance to choose in order to balance both cost and latency. Traditionally, this would involve deploying and testing several different model deployments using different instance types and sizes. For each deployment, you collect metrics such as latency, cost, and the maximum number of invocations each deployment can handle (Locust and JMeter are two common open-source load testing tools). Then you will have to go through each deployment and aggregate the data to compare. This iterative process is time-consuming , and sometimestake weeks of experimentation.
Newly released in December 2021, Amazon SageMaker Inference Recommender can help you solve this problem and decide what instance to use. It uses load testing to help optimize cost and performance in order to help you select the best instance and configuration to deploy your model with. This blog walks through an example of how to use Amazon SageMaker Inference Recommender in your machine learning workflow and shares tips we learned along the way.
If you have already deployed an endpoint for your model successfully, this article is for you. This article assumes that you have a packaged model with inference scripts in S3 from a previous model deployment. The whole end-to-end notebook can be found here.
Code Walkthrough
Inference recommender works with SageMaker Model Registry to test and compare the best instance types for a specific Model Package Version in Model Registry. So, before running the inference recommender, you need to use SageMaker Model Registry to create a model package group and register your model version to that package group. Then the Amazon Resource Name (ARN) of the registered model version is used when creating an inference recommender.
1. Importing packages and creating a model package group
The code below shows the packages that need to be imported. Since Amazon SageMaker Inference Recommender was just released at the end of 2021, you should make sure the SageMaker version is up to date, so it does provide the functionality of creating Inference recommender jobs. In this code walkthrough example, the version for SageMaker is 2.94.0 and Boto3 is 1.24.27.
We also create a sagemaker session and create a boto3 client for sagemaker.
import os
import sagemaker
from sagemaker import get_execution_role, Session
import boto3
region = boto3.Session().region_name
role = get_execution_role()
sm_client = boto3.client('sagemaker', region_name=region)
sagemaker_session = Session()
# check the sagemaker version
print(sagemaker.__version__)
If the SageMaker version is not correct, use below code to install the correct specified version. After running below command, do remember to restart the kernel in order to activate the new version.
!pip install --upgrade "sagemaker==2.94.0"
Below code shows how to create a model package group:
model_package_group_name = "inference-recommender-model-registry"
model_package_group_description = "testing for inference recommender"
model_package_group_input_dict = {
"ModelPackageGroupName": model_package_group_name,
"ModelPackageGroupDescription": model_package_group_description,
}
create_model_package_group_response = sm_client.create_model_package_group(
**model_package_group_input_dict
)
model_package_arn = create_model_package_group_response["ModelPackageGroupArn"]
print("ModelPackage Version ARN : {}".format(model_package_arn))
2. Preparing URL for model artifacts in S3
SageMaker models need to be packaged in a .tar.gz file. When your SageMaker Endpoint is provisioned, the files in the archive will be extracted and put in /opt/ml/model/ on the Endpoint. To bring your own Deep Learning model, SageMaker expects a single archive file in .tar.gz format, containing a model file (.pth) and the script (.py) for inference. If you have deployed your model or used it to do a batch transformation job, your model has already been packaged in this way. From a deployed endpoint, you can find the packaged model files by clicking on the deployed endpoint and navigating to "Endpoint configuration settings" > "Production variants" and clicking on the model name. From this page, you can find the S3 location of the model package in the section "Model data location"
Below, the code assigns a variable with the path to the model tar file stored in S3. This should be updated to point to the S3 path of your model artifacts.
model_url = "s3://sagemaker-us-east-2-*******/model/model.tar.gz"
3. Prepare sample payload files
After the model artifact is ready, a payload archive needs to be prepared to contain input files that Inference Recommender can invoke your endpoint. Inference Recommender will randomly sample files from this payload archive to call the endpoint so make sure it contains a similar distribution of input payloads expected in production. Note that your inference code must be able to read in the file formats from the payload archive, so basically the input format would be the same as what you would use when you invoke the endpoint from notebook cell directly.
Below are steps to zip this payload file. In this example, the payload folder contains six different testing images in png format.
- Create a local folder “sample_payload” in your working directory on SageMaker instance; Identify a variety of sample payload input files and upload them to this folder
!cd ./sample-payload/
- Run below command to get a payload tar file
payload_archive_name = "payload_images.tar.gz"
!tar czvf ../{payload_archive_name} *
- Upload this payload tar file to S3
sample_payload_url = sagemaker_session.upload_data(path="payload_images.tar.gz", key_prefix="test")
print("model uploaded to: {}".format(payload_data_url))
4. Register model in the model registry
As mentioned above, Inference Recommender works with a specific model package version in your Model Registry. This next section walks through creating a new model package version. We are going to use the boto3 sagemaker session we started above to submit our model package version to the model registry.
Inference recommender requires some additional parameters to be defined in your model package version in Model Registry. You can see a list of the required parameters to register a model package version in the boto3 documentation page here. In addition to the parameters listed as required here, using inference recommender also requires that the following parameters are defined:
- Domain - the ML domain of your model package, domains supported by inference recommender: 'COMPUTER_VISION' | 'NATURAL_LANGUAGE_PROCESSING' | 'MACHINE_LEARNING'
- Task - the task your model accomplishes, tasks supported by inference recommender: 'IMAGE_CLASSIFICATION' | 'OBJECT_DETECTION' | 'TEXT_GENERATION' | 'IMAGE_SEGMENTATION' | 'FILL_MASK' | 'CLASSIFICATION' | 'REGRESSION' | 'OTHER'
- SamplePayloadUrl - the payload S3 URL from step 3.
- Framework - the framework used by your model package.
- FrameworkVersion - the version of the framework used by your model package.
In the code sections below, we are preparing an input dictionary which contains all these required parameters, then submitting it to the model registry using boto3.
Note: Select the task that is the closest match to your model. Choose OTHER if none apply.
Let's start with some of the basic details of our model package. Here we are using a pytorch model running on pytorch version 1.8.0. It is an image segmentation model so we will use the parameters below.
framework = "pytorch"
framework_version = "1.8.0"
model_name = "my-pytorch-model"
ml_domain = "COMPUTER_VISION"
ml_task = "IMAGE_SEGMENTATION"
create_model_package_input_dict = {
"ModelPackageGroupName": model_package_group_name,
"Domain": ml_domain.upper(),
"Task": ml_task.upper(),
"SamplePayloadUrl": sample_payload_url,
"ModelPackageDescription": "{} {} inference recommender".format(framework, model_name),
"ModelApprovalStatus": "PendingManualApproval",
}
The next steps set up the inference configuration specifications for your model package. This will provide information on how the model should be hosted.
First, we need to retrieve the container image which we will use to host our model. Here, we take the model image provided by SageMaker for pytorch 1.8.0, the framework we have defined above. We also need to select an instance type here, so that it knows whether we need a container image that uses GPU or CPU.
instance_type = "ml.c4.xlarge"
image_uri = sagemaker.image_uris.retrieve(
framework=framework,
region=region,
version=framework_version,
py_version="py36",
image_scope='inference',
instance_type=instance_type,
)
Next, we provide the other arguments for the inference specification, format the information in the required dictionary structure, and add it to the request dictionary.
Some parameters of note:
- SupportedContentTypes - defines the expected MIME type for requests to the model. This should match the Content-Type header used when invoking your endpoint. You can find more information about the data formats used for inference with SageMaker here.
- SupportedRealtimeInferenceInstanceTypes - a user provided list of instance types that the model can be deployed to. Inference recommender will test and compare these models; if not provided, inference recommender will automatically select some instance types.
modelpackage_inference_specification = {
"InferenceSpecification": {
"Containers": [
{
"Image": image_uri, # from above
"ModelDataUrl": model_url,
"Framework": framework.upper(), # required
"FrameworkVersion": framework_version,
"NearestModelName": model_name
}
],
"SupportedContentTypes": ["application/x-image"], # required
"SupportedResponseMIMETypes": [],
"SupportedRealtimeInferenceInstanceTypes": ["ml.c4.xlarge", "ml.c5.xlarge", "ml.m5.xlarge", "ml.c5d.large", "ml.m5.large", "ml.inf1.xlarge"], # optional
}
}
# add it to our input dictionary
create_model_package_input_dict.update(modelpackage_inference_specification)
Finally, the code below is used to register the model version using the above-defined specification.
create_model_package_response = sm_client.create_model_package(**create_model_package_input_dict)
model_package_arn = create_model_package_response["ModelPackageArn"]
print('ModelPackage Version ARN : {}'.format(model_package_arn))
5. Create a SageMaker Inference Recommender Job
Now with your model package version in Model Registry, you can launch a 'Default' job to get instance recommendations. This only requires your ModelPackageVersionArn and creates a recommendation job which will provide recommendations within an hour or two. The result is a list of instance types and associated environment variables, with the cost, throughput, and latency metrics as observed by the inference recommendation job.
import time
default_job_name = model_name + "-instance-" + str(round(time.time()))
job_description = "{} {}".format(framework, model_name)
job_type = "Default"
rv = sm_client.create_inference_recommendations_job(
JobName=default_job_name,
JobDescription=job_description, # optional
JobType=job_type,
RoleArn=role,
InputConfig={"ModelPackageVersionArn": model_package_arn},
)
6. Check the Instance Recommendation Results
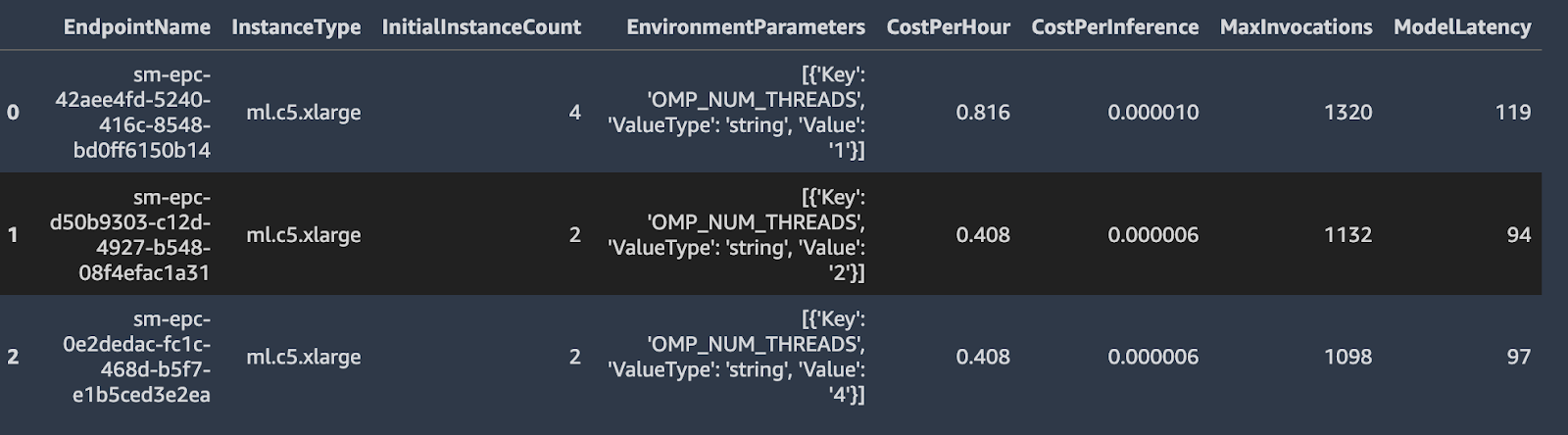
By running the code below, you can see the performance metrics comparison table, including:
- MaxInvocations - The maximum number of InvokeEndpoint requests sent to an endpoint per minute. Units: None
- ModelLatency - The interval of time taken by a model to respond as viewed from SageMaker. Units: Milliseconds
- CostPerHour - The estimated cost per hour for your real-time endpoint. Units: US Dollars
- CostPerInference - The estimated cost per inference for your real-time endpoint. Units: US Dollars
Depending on how many instances types specified for running the inference recommender, the whole process can take hours. In this example, it takes about 1 hour. There are two ways to view the progress of the job. The first method is to go to under the “SageMaker resources” -> “Inference Recommender Jobs”, where you can view the status of the job created as below screenshot shows.
The second way is to run below code block.
import pprint
import pandas as pd
finished = False
while not finished:
inference_recommender_job = sm_client.describe_inference_recommendations_job(
JobName=str(default_job_name)
)
if inference_recommender_job["Status"] in ["COMPLETED", "STOPPED", "FAILED"]:
finished = True
else:
print("In progress")
time.sleep(300)
if inference_recommender_job["Status"] == "FAILED":
print("Inference recommender job failed ")
print("Failed Reason: {}".format(inference_recommender_job["FailureReason"]))
else:
print("Inference recommender job completed")
Below code is used to extract the comparison metric esults for different instances.
data = [
{**x["EndpointConfiguration"], **x["ModelConfiguration"], **x["Metrics"]}
for x in inference_recommender_job["InferenceRecommendations"]
]
df = pd.DataFrame(data)
df.drop("VariantName", inplace=True, axis=1)
pd.set_option("max_colwidth", 400)
df.head()
Below figure shows an example of the comparison table, which helps you choose which instance type to use for endpoint deployment.
Additional Tips
Here are some additional tips and recommendations when using Inference Recommender.
1) Your inference script that is deployed with the model should not need any changes to work with SageMaker Inference Recommender. You can point directly to the model.tar.gz file with the packaged inference script that you use to do batch transformation or deploy an endpoint.
2) When zipping sample payload files, do it on SageMaker instead of in your local environment. Differences in operating systems may lead to the format being different when zipping, and may be unable to be read when running inference recommender.
3) When you retrieve the image URI from SageMaker, you must provide an instance type. This is used to determine if the inference instances will be using GPU or not, so that AWS knows whether you want the GPU image or CPU image. There is also a GitHub repository which gives details on the deep learning container images that are provided by AWS, you can find it here.
4) The example illustrated in this blog uses the default load testing built in the Inference Recommender. Inference recommender also allows you to do customized load testing, as this link provides some examples, such as tuning the environment variables.
Conclusion
This article has walked through the main code components for running SageMaker Inference Recommender for a model which has been registered with SageMaker Model Registry. Using SageMaker Inference Recommender can reduce the time and effort in choosing which instance type should be used. Additionally, Inference Recommender gives us some useful metrics about how our model will work once it’s deployed, such as the average latency, cost per hour and cost per inference, as well as the maximum number of invocations the deployment can handle.
FAQ
- How do the cost and performance of recommended instances compare with manually selected instances for common model types?
The Amazon SageMaker Inference Recommender optimizes instance selection through an extensive evaluation of performance and cost, often leading to more cost-effective and efficient outcomes than manual selections. This tool analyzes model requirements against various instances, balancing performance needs and budget constraints. By automating this analysis, SageMaker helps avoid the time-consuming trial and error that accompanies manual instance selection.
- Are there any limitations or considerations when using Amazon SageMaker Inference Recommender with very large or complex models?
When deploying very large or complex models using Amazon SageMaker Inference Recommender, it's important to consider potential limitations, such as the computational resources required by the model and the compatibility of certain instance types. Large models may necessitate instances with higher memory and processing capabilities, which might not be covered in the initial recommendations. Users should evaluate the recommended instances' specifications against their model's requirements to ensure optimal performance.
- Can Amazon SageMaker Inference Recommender be integrated with automated deployment pipelines, and if so, what are the best practices?
- Amazon SageMaker Inference Recommender can be integrated into automated deployment pipelines, streamlining the model deployment process. Using SageMaker's API, developers can programmatically retrieve instance recommendations and incorporate them into their CI/CD pipelines. This integration facilitates continuous delivery and deployment practices, allowing for the seamless selection of optimal instances as part of the model deployment workflow. Adopting best practices for automation, such as defining clear criteria, for instance, selection and ensuring robust testing mechanisms, enhances the effectiveness of using Inference Recommender in automated environments.



