Technical debt is a major issue that every company faces when migrating to the cloud. For many companies, tech debt is simply a cost of doing business – but it doesn’t have to be. Migrating to AWS isn’t just an opportunity for you to upgrade your infrastructure, it’s an opportunity to upgrade how you do business.
Eventually, everything fails – hardware, code, it doesn’t matter. Even Amazon Web Services EC2 up-time guarantee is 99.95%, but you can engineer with redundancy and automation in mind to overcome this. Implementing these methods though, requires moving past being married to individual servers, pieces of hardware or data centers. We now architect systems with failure in mind and then build for rapid recovery of stack components.
A common mistake we see while consulting are companies that do a basic “lift and shift” when migrating themselves to the cloud. It’s easy to spin up servers identical in spec to the one in your server room, but that means bringing your baggage with you: poorly optimized instances, unused storage and more.
We know, we’ve been there. When we first migrated, all of our servers were named after Simpsons characters and craft beers. Those were pets of ours, but it made a lot of things go more smoothly when we renamed the “Milhouse” server to “Mail.” At least, it made things a lot easier for our new hire when they first heard someone in the bullpen yell, “Milhouse is down!”
By naming them, we became more attached too – often to a detriment. Up-time doesn’t need to be a high score you’re trying to achieve when you know resetting the server once a month at midnight keeps everything running smoothly.

Here’s our solution: build a CI/CD pipeline.
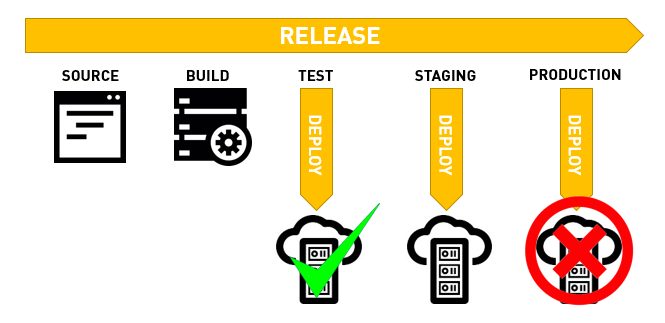
CI/CD Pipeline
Building an automated assembly line gives you the freedom of decoupling resources from one another. Deploy a new copy of your stack every time for testing, while utilizing modular components allows you to begin auto-scaling. Stop paying for unused compute power and start building for automation – and think of your infrastructure as cattle.
By building a Continuous Integration and Continuous Delivery pipeline, you can begin with basics of DevOps methodology that helps you build a stronger foundation for your future. A CI/CD pipeline allows you to build, test and deploy your infrastructure – and liberates you from keeping a single production pet server running 24/7. Instead, you’re free to make incremental improvements and testing, allowing you to pay down technical debt along the way – without doing extensive, time consuming releases.
If you know there is a memory leak in the app server, you shouldn’t have to set a weekly reminder to restart it. Instead, you can kill it and respawn an identical copy. Then, if you know it happens every fifth day of running – automate the procedure to respawn it every fourth day (preferably when you know usage is down). This gives your users a better experience and you peace of mind since you won’t be worrying about someone inevitably forgetting to do it.
Then you log the bug and let your developers do the research into the root of the problem before it becomes a bottleneck in production.