
Blog
This article is the last in our series taking a deep look at Amazon's Well-Architected Framework, which is an incredible collection of best practices for cloud-native organizations. This month, we're digging into the Performance Efficiency Pillar.
Over the last 15 years, I've worked on many technical teams in a variety of roles, and one of the most common challenges those teams faced was performance. In the world of traditional, on-premise environments, achieving performance goals in an efficient way can be quite challenging. One of the hallmark innovations of cloud infrastructure is the ability to rapidly scale up and down to maintain consistent performance, regardless of demand, and to align your spend with your usage.
AWS' Well-Architected Framework is one of the best collections of best practices available for organizations in the midst of a cloud transformation. The "Performance Efficiency" pillar of the Well-Architected Framework introduces itself thusly:
The performance efficiency pillar focuses on the efficient use of computing resources to meet requirements and how to maintain that efficiency as demand changes and technologies evolve. This paper provides in-depth, best-practice guidance for architecting for performance efficiency on AWS
Practically speaking, performance can be achieved in a number of ways, but achieving performance goals efficiently is uniquely challenging, as it forces technology teams to take a more nuanced and deliberate approach. Organizations that have fully embraced the principles and best practices outlined in the Performance Efficiency pillar of the Well-Architected Framework will:
- Embrace the availability of emerging technologies as fully managed services, reducing their management burden.
- Make use of serverless architectures to enable scale and reduce operational overhead.
- Constantly be experimenting with new techniques, configurations, instance types, services, and more.
- Leverage a global footprint of edge locations and regions to reach their customers.
Let's dive into the Performance Efficiency Pillar of the Well-Architected Framework to learn more about the best practices contained within.
If you're interested in learning about the birth of the AWS Well-Architected Framework, then check out our initial post, "Introducing the AWS Well-Architected Program."
Design Principles
Amazon outlines six design principles for achieving performance efficiency:
- Democratize advanced technologies
- Go global in minutes
- Use serverless architectures
- Experiment more often
- Mechanical sympathy
Democratize Advanced Technologies
In traditional, on-premise environments, adopting emerging technologies like NoSQL databases, media transcoding systems, and machine learning tools can be difficult because of the overhead of learning how to build, deploy, and manage the technology. In the cloud, many of these technologies are now available to consume as a service, eliminating the overhead and distraction of provisioning and management. By adopting these services, you can accelerate your team's ability to take advantage of new technologies, improving the quality and performance of the product you deliver to your customers.
Go Global in Minutes
Businesses are increasingly finding their customer bases are globally distributed, creating a performance challenge for applications that are hosted in a small number of data centers. With AWS, you can take advantage of large number of global Regions and Edge Locations to provide lower latency, higher performance service to your customers at a low cost.
Use Serverless Architectures
In addition to adopting AWS managed services like RDS, Elemental, and ElastiCache, which remove the burden of software management, serverless architectures are enabling businesses to shed even more operational overhead. By leveraging serverless architectures using services like S3, Lambda, and API Gateway, you can eliminate the need for server management.
At Mission, we manage hundreds of workloads for our customers, including the management of servers that drive their applications. When serverless isn't practical for a particular workload, consider engaging with a managed service provider like Mission, who can free you from management tedium, giving you the ability to focus on your customers.
Experiment More Often
Innovation is driven by creativity, yet too often technical teams find themselves mired in management tasks, especially when their workloads are shackled to the data center. In my years of management of product teams, I've found experimentation to be the best driver of creative innovation. The cloud provides on-demand IT resources that are fully automatable, giving your teams the power to experiment and create more often. With regular experimentation will come improvements in performance, security, and quality.
Mechanical Sympathy
The final design principle for performance efficiency is "mechanical sympathy," which is the concept of aligning your technology approach with your goals. AWS offers a huge breadth of services to choose from, and its critical to diligently evaluate which services are best matched with your goals.
Using these design principles, you can help drive performance efficiency within your organization.
Areas of Focus for Performance Efficiency
Amazon describes performance efficiency in the cloud through four key areas of concern:
- Selection
- Review
- Monitoring
- Trade-offs
AWS recommends taking a data-driven approach to achieving your performance goals. Start by collecting data that impacts your architecture, and review it on a regular basis to ensure that the choices you made in the past are still the right ones as the AWS Cloud continues to evolve. Deploy effective monitoring to rapidly detect and action performance issues, and finally be willing to make tradeoffs in your architecture, such as caching and compression, to improve performance.
Selection
AWS currently provides dozens of services with hundreds of features, configurations, and options. While this can seem daunting, the richness of AWS' Cloud is precisely what makes it so capable for handling many different types of workload. When architecting systems, keep in mind that "one size fits all" doesn't apply to well-architected workloads. You'll need to consider the entire breadth of the AWS catalog, choosing the best approaches, services, and configurations that meet the needs of your particular workload.
AWS provides AWS Solutions Architects and AWS Reference Architectures to help guide you, but AWS strongly recommends working with an AWS Partner. Mission has been architecting and managing workloads for our customers for years, and with our experience and expertise, we can help you choose an appropriate architecture, including assistance with benchmarking and optimization.
Most systems require a multifaceted approach, combining several architectural patterns (such as event-driven, ETL, request-response, or pipeline) where appropriate to create a high-performing system. AWS outlines four key categories of resources to consider in this process: compute, storage, database, and network.
Compute
In AWS, compute takes center stage, with three main types of compute – instances, containers, and functions. Your goal in the selection process is to choose the right blend of these compute types that help you maintain consistent performance as demand changes. Each compute type offers differing elasticity mechanisms, so consider carefully.
Instances are the most familiar and common option, while containers help with resource packing and utilization. Functions are the new kid on the block, and are extremely useful for event-driven and highly parallelizable components.
Instances
Amazon EC2 provides virtualized servers called instances in a variety of families and sizes, with options for GPUs, FPGAs, burstability, and more. Because EC2 instances are virtualized and completely API-driven, you have the ability to change resource decisions over time to take advantage of new capabilities, or to adjust to changes in demand.
When evaluating EC2 instance families and types, consider how the compute, memory, and storage capabilities will impact your overall system performance, while also taking into account the cost impact of your choices.
AWS provides burstable instance families that are helpful for workloads that generally require a moderate level of CPU performance, with the occasional need to burst up to significantly higher performance. These instances are great for general purpose workloads, such as web servers or developer environments. When a burstable instance is in steady state, CPU credits accumulate that can then be consumed when demand rises.
In addition to instance types and families, you also must consider additional configuration options provided by Amazon.
AWS supports Graphics Processing Units (GPU) which can be leveraged by platforms such as CUDA to handle highly parallel tasks, 3D rendering, and video compression. In many cases, using GPU hardware acceleration can improve performance while reducing costs.
Field Programmable Gate Arrays, or FPGAs, provide custom hardware-accelerated execution. Your developers can build algorithms in languages like C, Go, Verilog, and VHDL, and then take advantage of FPGA acceleration.
Finally, AWS EC2 gives you access to advanced computing features available in modern CPUs such as turbo-boost, co-processors for cryptography, and AVX extensions.
With so much to consider when selecting instance types for your workload, AWS advises that you collect and leverage data to drive your decision.
Containers
While instances provide virtualization and isolation at the server level, containers provide it at the operating system level, enabling the deployment of an application in resource-isolation. Amazon provides several container-centric services.
Amazon EC2 Container Service, or Amazon ECS, is a fully managed container service that provides automated execution and management of containers on a cluster of EC2 instances. ECS is well integrated with the rest of AWS, including Auto Scaling, which provides metrics-based scaling of your services by scaling the number of containers and backing EC2 instances up and down based upon demand. Amazon ECS also is integrated with Elastic Load Balancing (ELB) to ensure traffic is balanced across your services in your container fleet dynamically. In addition to Amazon ECS, AWS provides the Amazon Elastic Kubernetes Service, or Amazon EKS, which provides a fully managed Kubernetes environment. Amazon EKS is similarly well integrated with the rest of AWS, and gives you access to the full power of Kubernetes.
Similar to your selection process for instances, AWS recommends a data-driven approach to identify your container strategy.
Functions
While instances and containers give you full control over the execution environment for your application code, functions completely abstract that environment away, enabling you to execute code without running or managing servers or containers.
AWS Lambda pioneered "functions as a service" when it was introduced in November 2014, and has completely changed the way we think about compute. With AWS Lambda, your developers simply upload their application code, and set it up to be triggered by events from other AWS services, direct function execution, or by exposing it as a web service using Amazon API Gateway.
The combination of AWS Lambda and API Gateway have become my go-to method for building out microservices. API Gateway makes it easy to define, create, publish, and monitor a secure API at massive scale, with AWS Lambda functions providing the business logic. Scaling an application with AWS Lambda and API Gateway is much more straightforward than it is with instances and containers, as functions can be executed in massive parallel, with the API Gateway handling the scaling of the HTTP layer.
AWS Lambda has few configuration options: the amount of memory for a function and the maximum execution time. To optimize performance, you'll have to remember that the CPU power of a function is proportional to the amount of memory.
Elasticity
Before we move on from compute, its important to discuss the concept of elasticity, which is the ability to align resource supply with demand for those resources. Instances, containers, and functions all have mechanisms for elasticity, and its important to consider the impact of those mechanisms.
For example, with instances and containers, elasticity is largely achieved using Auto Scaling. However, instances and containers both require provisioning time, and individual instances sometimes suffer from failures. You'll need to take into account provisioning time as you build out automation for elasticity. With functions, achieving elasticity is more straightforward as AWS handles scaling the underlying infrastructure for you.
More more detail on elasticity and matching supply with demand, I recommend you read my blog post on the Cost Optimization Pillar of the Well-Architected Framework, or watch our webinar.
Storage
Storage in AWS comes in many forms, spanning the gamut of object, block, and file, with a variety of performance characteristics, options, configurations, and constraints. Selecting the right storage solution for your applications and systems thus requires the same diligence as compute, taking a data-driven approach, and potentially leveraging partners like Mission to help guide your way.
AWS recommends driving your selection process by considering:
- Characteristics – Each type of storage has varying characteristics for latency, throughput, and shareability.
- Configuration Options – Optimizing your storage for your workload using tunables and options.
- Access Patterns – What are the throughput requirements for your applications? Are you more concerned about storage cost or performance? How will you access the data on your storage?
AWS provides this useful table in their Performance Efficiency white paper, which provides a nice overview of the varying characteristics of each type of storage:
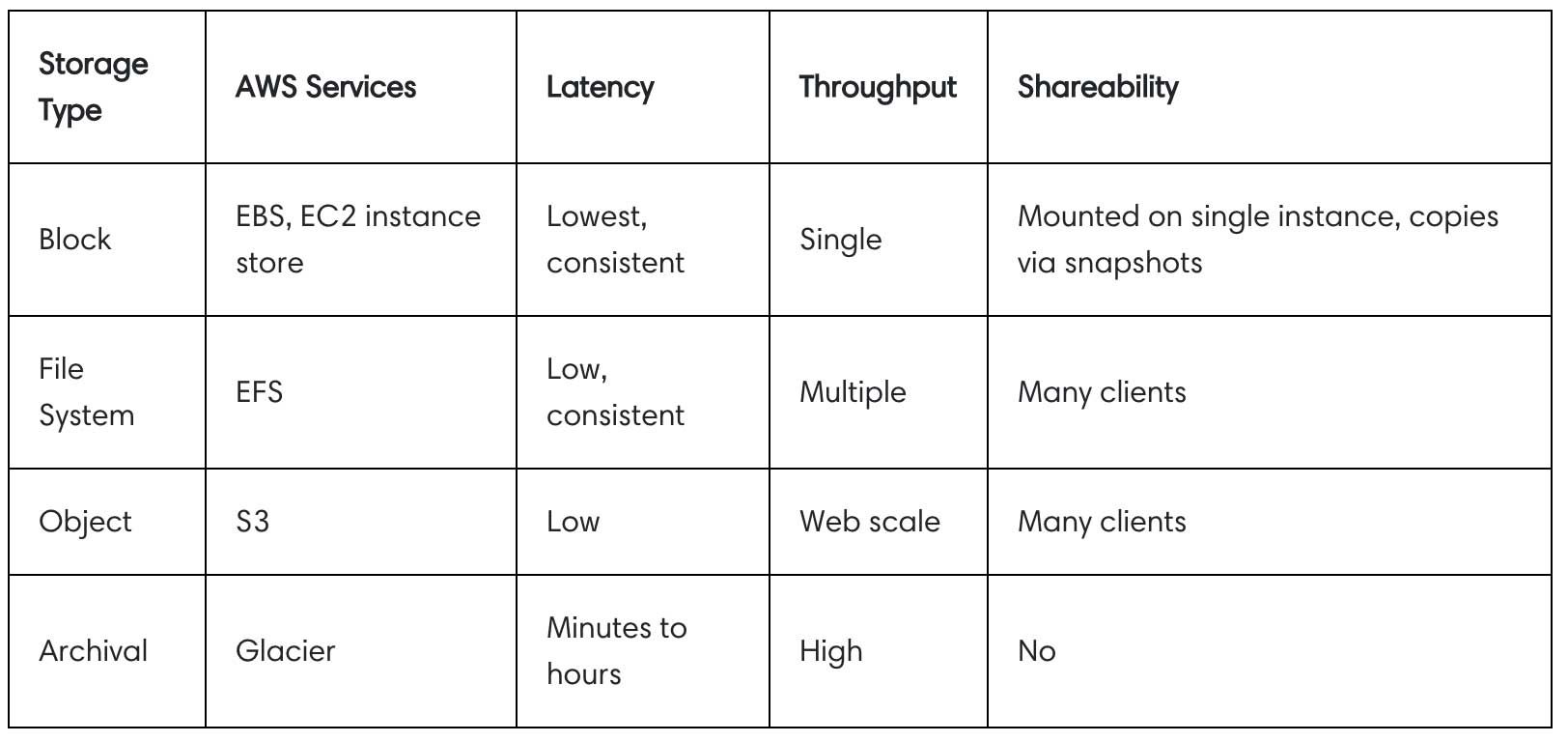
Block storage is ideal for workloads where data is accessed by a single instance with high IOPS and low latency requirements. If data needs to be accessed by multiple instances, consider EFS. For massively distributed systems, Amazon S3 supports nearly unlimited simultaneous clients. When cost is the primary consideration, archival stores like Glacier are appropriate.
Once you've selected the appropriate storage types for your system based upon their characteristics, you need to consider your configuration options. All of the above storage types have some level of configuration option to consider. Amazon EBS, for example, provides the option of SSD-backed or HDD-backed storage, depending on your IOPS requirements. In addition, SSD-backed volumes provide the option for Provisioned IOPS for latency-sensitive transactional workloads. With Amazon S3, you should consider transfer acceleration, redundancy level, and integration with CloudFront for global distribution. Finally, consider implementing lifecycles for your S3 storage to transition cold data to lower cost configurations over time.
The final consideration for storage is how you access your data. Selecting the solution that aligns best to your access patterns will help you create a well-performing system. For example, consider creating RAID 0 arrays with your EBS volumes to achieve a higher level of performance.
Database
As with storage and compute, AWS offers a broad selection of database services that can help you meet your performance goals. You'll need to understand your requirements for consistency, latency, availability, durability, and more when evaluating database solutions, so AWS again encourages a data-driven approach.
In traditional, on-premise environments, there is often a desire to standardize on a single database platform to reduce management overhead. Because AWS provides databases as fully managed services, you are instead able to make use of multiple approaches and technologies to better meet the needs of different parts of your system.
AWS encourages you to consider four key factors when selecting your database technology:
- Access patterns – As with storage, the way that you access data in your database systems can have significant impact on their performance, so it is important to select a solution that fits your access patterns, or to adapt your access patterns to maximize performance. You'll need to consider factors such as indexes, partitioning, and horizontal scaling.
- Characteristics – Are availability, consistency, latency, durability, or query capability important factors in your selection? Understand your requirements and then familiarize yourself with AWS' database offerings to select the appropriate approach. In many cases, a combination of relational, NoSQL, and data warehousing will be required to fully achieve your goals.
- Configuration options – Each database solution that you employ will have a number of configuration options to consider that can impact performance.
- Operational effort – Managing and maintaining a database can be extremely challenging. Consider using AWS' fully managed database services to reduce your operational effort.
Armed with a deeper understanding of your requirements, it is time to understand the four primary database technologies: Relational Online Transaction Processing (OLTP), non-relational databases (NoSQL), data warehousing and Online Analytical Processing (OLAP), and data indexing and searching.
Relational Online Transaction Processing (OLTP)
OLTP encompasses most popular traditional relational databases, such as MySQL, PostgreSQL, Oracle, and Microsoft SQL Server. Relational databases provide rich query support, high-performance, relational modeling, and sophisticated transaction support. With AWS, you can run RDBMS software on an EC2 instance, or adopt Amazon Relational Database Service (Amazon RDS), which provides is a fully managed service.
For optimizing self-managed RDBMS solutions on EC2, you'll need to optimize the EC2 instances themselves (compute, memory, storage, network), the operating system and settings, the database system configuration, and the databases themselves.
Relational database systems can require a significant amount of tuning, configuration, and management, so AWS recommends embracing Amazon RDS to reduce that managemenet burden. You'll then be able to focus on optimizing by using RDS configuration options and tuneables, and within the database itself, via schema updates, indexing, views, and more. For read-heavy workloads, consider creating read replicas to distribute load, or taking advantage of Amazon RDS' automated read replica support, SSD-backed storage options, and provisioned IOPS.
In addition to the traditional database engines supported by Amazon RDS, you have the choice of using Amazon Aurora, which is compatible with a variety of relational databases, and is a cloud-native system purpose-built for AWS, providing improved performance, and freedom from licensing constraints.
Non-Relational Databases (NoSQL)
Relational databases have served us well, and can scale up to handle a huge variety of workloads. That said, non-relational databases provide scalable, distributed platforms that are well-suited for massive scale and workloads with less structured data.
While NoSQL databases can aid in performance, it's important to note that their query languages and capabilities tend to be less capable than RDBMS solutions, which pushes more complexity into the application layer.
NoSQL solutions like Cassandra and MongoDB can be run on EC2 instances. Amazon also provides Amazon DynamoDB, which is a fully managed NoSQL database designed for extremely low latency and high performance at any scale. With DynamoDB, you can specify precise requirements for read and write operations per second, and storage scales up and down automatically. DynamoDB also offers the DynamoDB Accelerator (DAX), which is a distributed cache tier for improving performance. To optimize your usage of DynamoDB, carefully employ indexes, partition keys, and attribute projection.
Data Warehouse and Online Analytical Processing (OLAP)
For application workloads, OLTP and NoSQL platforms are excellent choices, but they are generally too limited when it comes to large scale analytics. Data warehouse platforms are designed for digging deep into structured data, and are generally a better solution for these use cases.
It is possible to self-hosted data warehousing solutions from Microsoft, Pivotal, or Oracle on EC2, but this creates a significant burden for configuration, optimization, and maintenance. Instead, consider using Amazon Redshift, which is a fully managed data warehouse solution capable of petabase-scale. Amazon Redshift allows for controlling the number of nodes in your data warehouse, including "dense compute" (DC) nodes for high performance. Optimizing Amazon Redshift for performance requires tuning your selection of sort keys, distribution keys, and column encodings. If you have data stored in S3, you can take advantage of Amazon Redshift Spectrum, which is a query engine for acting on S3 data lakes. If your S3 data lake contains lightly structured data, consider using Amazon Athena, which is a fully-managed Presto service that is integrated with Amazon Glue's data catalog.
Data Indexing and Searching
Indexing and searching of content at scale is another use case that requires specialized technology to do efficiently. There are a number of open source and commercially available tools, such as Apache Lucene and Elasticsearch, which can index documents at scale and make them searchable and available to reporting platforms like Kibana. It is possible to deploy these technologies to EC2 instances, but yet again, this introduces significant management overhead. Amazon Elasticsearch Service (Amazon ES) is a fully managed Elasticsearch service for your applications that has built-in, powerful scaling features that are easy to control and automate.
Network
The final category to consider in the resource selection process is the network. In AWS, networking is completely virtualized, and many AWS services offer a variety of product features that help optimize your network traffic to your use case, including Amazon S3 transfer acceleration, enhanced networking EC2 instance types, and more. In addition, AWS provides specialized networking features to address latency.
Creating an optimized, performant, and efficient network requires considering three major factors: location, product features, and networking features.
Location
Latency is driven in large part by the speed of light, so choosing an AWS Region close to your users ensures that your users will have a better experience when using your applications. That said, it's also important to consider the location of your data to avoid transferring large amounts of data from storage to compute over long distance.
Another way to reduce latency is to take advantage of AWS Cloud's extensive global presence of edge locations. CloudFront is a global CDN that will accelerate delivery of both static and dynamic content by delivering it from these edge locations. Route 53 is AWS Cloud's distributed, highly available DNS service, which is built on top of these edge locations. By using edge services, you can reduce latency, improve performance with caching, and more.
Amazon EC2 provides placement groups, which are logical groupings of instances within an Availability Zone. When instances are grouped together in this way, they are connected via a low-latency, high-speed (20 Gbps) network. Use placement groups for applications that are sensitive to network latency, or require high network throughput.
Product Features
AWS Cloud provides a number of product features to improve networking performance.
- Amazon S3's content acceleration feature lets users leverage edge locations to upload content into S3.
- EC2 instances have access to enhanced networking, which accelerates networking performance using a network device virtualization technology called SR-IOV.
- Amazon Elastic Network Adapters (ENA) delivers 20 Gbps network capacity to instances in a placement group.
- Amazon EBS-optimized instances ensure the best I/O performance with optimized configuration and dedicated capacity.
Networking Features
In addition to product specific features, AWS Cloud supports a variety of network features that can improve performance by reducing network distance or jitter.
- Route 53 offers latency-based routing (LBR) by routing user traffic to the AWS Region that will deliver them the best experience.
- AWS Direct Connect offers dedicated connectivity into AWS data centers, at speeds up to 10 Gbps.
- Amazon VPC endpoints eliminate the need for internet gateways or NAT instances.
- AWS Cloud offers Application Load Balancers and Network Load Balancers as part of Elastic Load Balancing to serve a variety of use cases, from routing HTTP(s) traffic to high-throughput TCP traffic.
Review
The one constant in technology is change, and AWS Cloud is perhaps the best example of this principle, as it is continually evolving at an ever-accelerating pace. In addition to the environment changes to consider, your applications and usage patterns will evolve, so it's important to put in place a continuous performance review process that ensures that your resource selection remains optimal.
AWS outlines a data-driven approach that considers the following factors:
- Infrastructure as code – By using IaC tools like AWS CloudFormation and Terraform, you make it easier to review, change, and track your infrastructure as you test and make changes during the review process.
- Deployment pipeline – Using CI/CD pipelines to deploy helps you make deployment repeatable as you iterate.
- Well-defined metrics – Creating solid KPIs and monitoring helps validate and test changes. Be sure to choose effective metrics.
- Performance test automatically – Automatically trigger performance tests as part of your deployment pipeline. Consider leveraging AWS Spot Instances to make this process more cost effective.
- Load generation – Script typical user interactions and then use these scripts to simulate load.
- Performance visibility – Surface your KPIs to your team. Visibility drives accountability and improvement.
- Visualization – Overlay performance metrics over your architecture diagrams to help accelerate issue identification.
Once you've implemented a performance review process, it can be evolved over time as you improve your testing skill set and techniques.
Benchmarking
Benchmarking is another critical component of review. Using synthetic tests, you can collect data on the performance of your system and its' components to drive continuous improvement. Note that benchmarking differs from load testing, as it's lighter weight and can be performed at the start of a new project, before you have a complete system to load test.
Follow your performance review process when benchmarking, leveraging a downscaled version of your deployment pipeline that focuses on your benchmarks. Custom benchmarks and industry standard tests like TPC-DS can both be employed. Be sure to pre-warm your test environment to ensure valid results, and run your tests more than once to capture variance. Benchmarks are most useful when evaluating changes to components of a service to see if a proposed change will have the desired positive impact or not.
Load Testing
Unlike benchmarking, load testing focuses on your actual workload, giving you a holistic picture of performance in production. When load testing, be careful to use scrubbed production data or synthetic data, and create scripted user interactions that are representative of real usage. Using these scripts, you can carry out load tests as part of your delivery pipeline, and use the results to compare against your KPIs. These thresholds can even be codified as Amazon CloudWatch metrics and alarms to alert when a test reveals performance issues.
Because AWS provides complete on-demand infrastructure, you can leverage your IaC and CI/CD pipelines to run production-scale tests of your architecture in a cost-effective way. Consider using Spot Instances to generate load at a very low cost. AWS recommends building performance requirements right into your user stories, and then scripting the most critical user stories as automated interactions to test them at scale. Finally, you should ensure that your load testing reflects the geographic distribution of your actual user base.
Monitoring
Once your architecture has been implemented, and has a performance review process in place, you will want to implement proactive performance monitoring. By leveraging your well-defined performance KPIs and automation, you can trigger alerts and remediation. Amazon CloudWatch is the central hub for this monitoring, and your automation can trigger actions in other AWS services like AWS Lambda or Amazon SQS.
There are two, complementary types of monitoring to consider: active and passive.
- Active monitoring (AM) uses simulated user activity in a continuous fashion to test performance and availability. AM can be run on your development, staging, and production environments to identify issues before they impact customers.
- Passive monitoring (PM) collects metrics based upon actual user activity, and can be segmented into geographies, user subsets, browsers, and more. PM is particularly useful for measuring user experience performance, geographic variability, and the impact of API use.
AWS divides monitoring into five distinct phases:
- Generation – define your metrics and thresholds
- Aggregation – collect data and combine it to create a holistic view
- Real-time processing and alarming – action your metrics
- Storage – manage data and retention
- Analytics – create dashboards and reports
CloudWatch is a critical service for enabling all five phases of monitoring, as it can collect and track metrics and create alarms not only for all AWS services and resources, but also for custom metrics for your applications and systems, including log files. Implementing deep monitoring on top of CloudWatch will help you react quickly, but be careful not to paralyze yourself with data – only alert on actionable issues, and schedule regular game days to conduct simulations for testing your environment.
Trade-offs
In my introductory Computer Science courses at Georgia Tech, I remember one of my professors instructing my class that software was nothing but a tug-of-war between different priorities. Nearly a third of the answers to questions on his exams involved the trade-off of "space vs. time," and in the world of cloud, trade-offs are more important than ever. In an ideal world, we'd be able to achieve durability, consistency, performance, and efficiency all at once, but that's sadly not the world that we live in, so it's time to get acquainted with the menu of trade-offs you can make to meet your goals.
AWS provides a handy overview of some trade-offs you should consider:
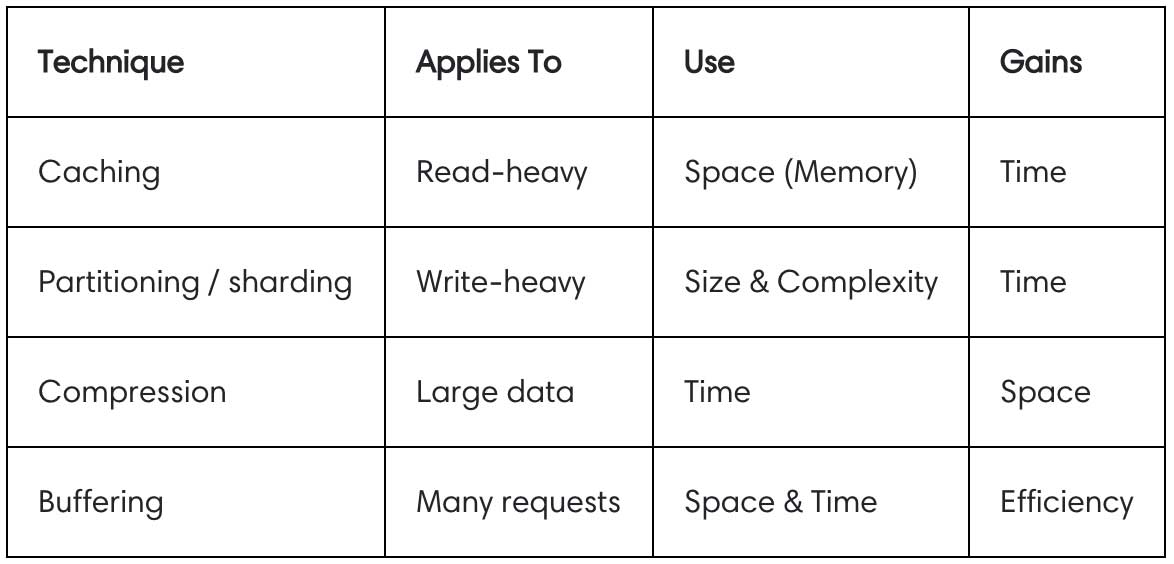
Let's dig in to each of these trade-offs to learn more.
Caching
Most applications rely on a centralized "single source of truth" for data, like a database, but often, as applications scale, it becomes increasingly difficult to eke out performance from that single source of truth, making it a bottleneck. Caching is an approach that trades space (duplicated data) for time (improved performance) that is especially useful in read-heavy workloads. There are several ways to approach caching:
- Application-Level Cache – Implementing this trade-off in your application code involves techniques like memoization and app-level caches. As requests are cached, execution time is reduced. In-memory or distributed caches can be implemented using platforms like Redis, Memcached, or Varnish, which can be deployed on Amazon EC2 or accessed as a fully managed service through ElastiCache. The main downside to an application-level cache is increased application complexity and the aforementioned increase is space requirements for duplicated data.
- Database-Level Cache – Read-only database replicas provide the ability to scale out beyond the limitations of a single database instance, which can be particularly useful for read-heavy workloads. The downside is database-level caching is additional complexity in your database, which can be mitigated by using Amazon RDS, which provides read replicas as a fully managed service. For latency-sensitive workloads, you can leverage RDS' Multi-AZ feature to specify which Availability Zones the read replicas are placed in. Database-level caches have the advantage of requiring little to no changes to application code.
- Geographic Level Cache – CDNs like Amazon CloudFront are another form of cache which trades space for time by replicating content at the edge to accelerate delivery. CDNs can also be employed for API acceleration and dynamic content.
Partitioning or Sharding
A common challenge with relational databases at large scale is when the database grows so large that it can no longer be contained within a single instance. Generally, database instances are scaled vertically by adding RAM, CPU, and storage. Once you've hit the maximum instance size, a trade-off will be needed to allow the system to continue to scale: data partitioning, also known as sharding.
Sharding is a technique where data is split across multiple, separate and distinct database schemas, each running in its' own autonomous instance. Sharding thus is a trade-off between size/complexity (additional database instances) and time (performance). Because sharding moves data around, your application code will need to be updated to understand how data is split between database shards, creating significant additional complexity.
NoSQL databases have an advantage over relational databases in this case, as they are capable of performing data partitioning in an automated, horizontal fashion transparently to the application.
Compression
For workloads where space is an issue, compression can be employed to trade time (compute for compressing and decompressing) for space (smaller footprint) and efficiency (lower bandwidth requirements). Compression is a technique that can be applied pervasively to static and dynamic data, including APIs.
Amazon has bundled compression support into CloudFront, enabling faster delivery and reduced bandwidth requirements. AWS Snowball is an appliance that can be used to transfer large amounts of data into and out of S3, and makes heavy use of compression. Similarly, Amazon Redshift makes use of compression with columnar storage.
Buffering
The final trade-off to consider is buffering, which is a technique of employing a form of queue to accept work requests. The advantage of buffering is that it separates the rate at which messages are being produced from the rate at which they are consumed.
AWS provides a number of services for buffering, including Amazon SQS and Amazon Kinesis, which implement a single-consumer and multi-consumer buffer, respectively. As discussed in our discussion of the Cost-Optimization Pillar, your Amazon SQS spend can be reduced by publishing to SQS in batches and fetching messages using long-polling. With Amazon Kinesis, you can implement a more sophisticated "publish and subscribe" architecture, where multiple consumers can subscribe to receive messages on a particular topic.
Conclusion
I hope this deep dive into performance efficiency has given you the tools necessary to meet your performance goals in a data-driven way, from selecting the right resource types, to implementing continuous performance review and monitoring, and finally making architectural trade-offs to improve performance efficiency. If you'd like to learn more about the AWS Well-Architected Framework, check out our webinar on the Performance Efficiency Pillar.
As an AWS Well-Architected Review Launch Partner, Mission processes assurance for your AWS infrastructure, processing compliance checks across the five key pillars. Reach out to Mission now to schedule a Well-Architected Review. Additionally, Mission Cloud offers a free tool called Cloud Score to benchmark your environment against the well-architected pillars defining best AWS practices.
FAQ
- How do organizations measure and benchmark performance efficiency before and after implementing the recommended best practices?
Organizations can measure and benchmark performance efficiency by utilizing a combination of AWS-native tools and third-party solutions. AWS CloudWatch provides detailed metrics on resource utilization, which can be compared against baseline performance data collected before the implementation of best practices. Additionally, AWS Trusted Advisor offers recommendations for improving performance efficiency. Benchmarking involves comparing these metrics against industry standards or historical performance data to identify areas of improvement and track progress over time.
- What specific challenges do companies face when transitioning to serverless architectures, and how can these be mitigated?
Companies transitioning to serverless architectures often face challenges such as managing cold start times, optimizing function execution times, and ensuring application security. Cold starts can be mitigated by keeping functions warm through scheduled invocations. Execution times can be optimized by fine-tuning function configurations and resource allocations. Security concerns are addressed by following the principle of least privilege and implementing identity and access management controls, ensuring that functions have only the permissions they need to operate.
- Can you provide case studies or examples of businesses that successfully improved their performance efficiency by adopting the principles outlined in the AWS Well-Architected Framework?
- There are several case studies of businesses that have successfully improved their performance efficiency by adopting the AWS Well-Architected Framework principles. For example, a financial services company rearchitected its customer-facing application to utilize serverless technologies, resulting in improved scalability and a 50% reduction in operational costs. Another case involved an e-commerce platform that implemented auto-scaling and optimized its use of Amazon S3 and Amazon CloudFront, significantly reducing page load times and enhancing customer satisfaction.
Go Back



Share this post