
Are you ready to take your machine learning training to the next level with Amazon SageMaker? In this blog post, we'll provide a comprehensive guide to help you get started. Whether you're used to working in Jupyter notebooks or local Python scripts, we'll walk you through the technical details of how model training on SageMaker works. This post also gives a brief introduction to the newly introduced ability to run local code as a SageMaker training job.
Amazon SageMaker primarily uses remote training jobs, which offers several benefits compared to training your machine learning model locally. Here are some advantages of remote training to consider:
- Scalability: Remote training jobs allow you to leverage the scalability of cloud resources. You can easily provision larger and more powerful instances enabling you to train with larger datasets, or create more complex models without being constrained by your local hardware limitations.
- Repeatability: SageMaker keeps a record of all of your training jobs, including what container was used to run the job, what hyperparameters were set, and what training data was used. Additionally, since training jobs are defined programmatically, you can version code used to deploy training jobs. This makes it easy to see exactly how your training job was run, and repeat the same experiment.
- Security: When training remotely, your training instance connects directly to your data in S3, so it never leaves the cloud. You won’t have to transfer large datasets to your local machine, which reduces the risk of data leakage or unauthorized access.
How does remote training work?
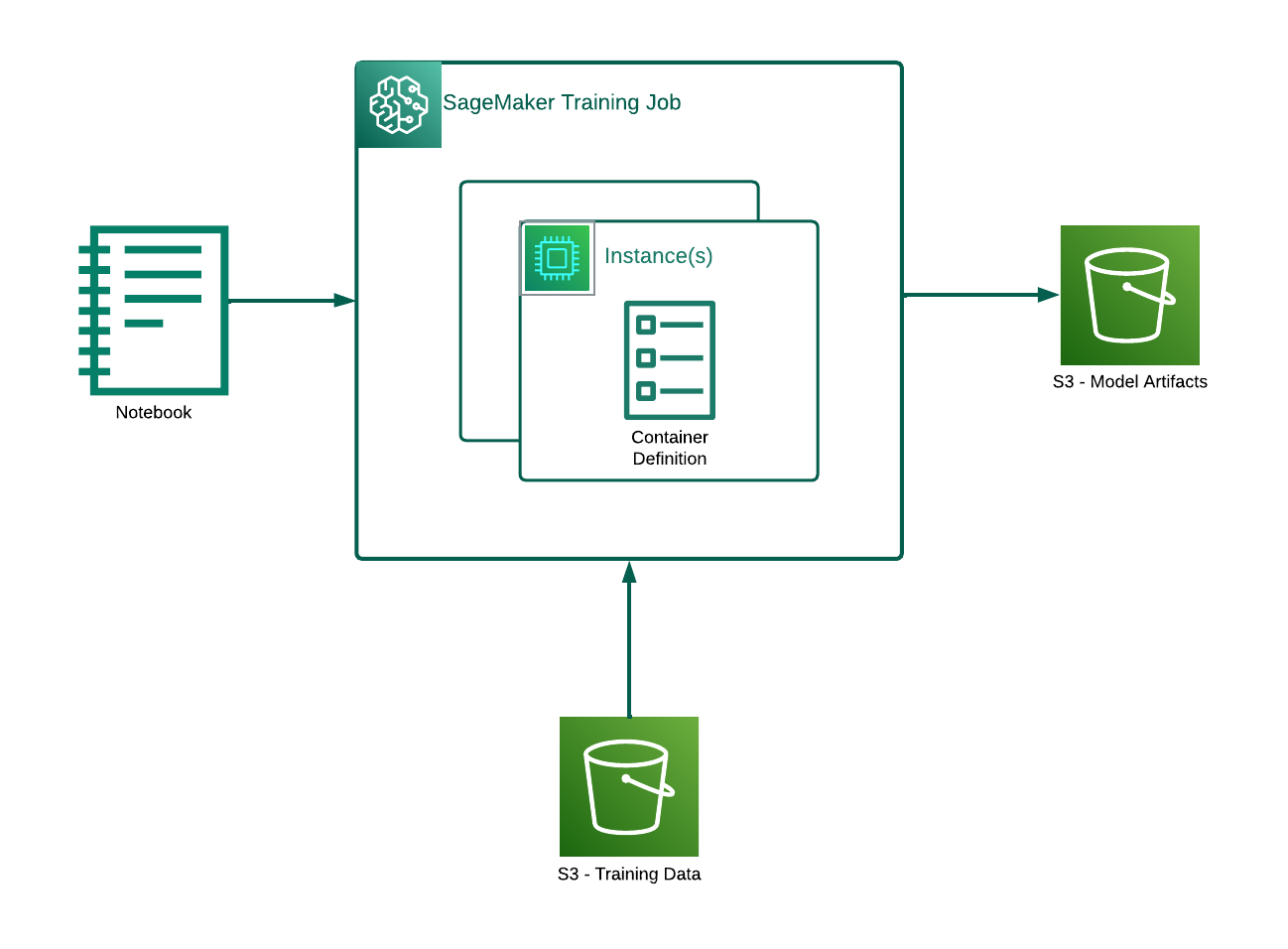
Let’s start by looking at the components of training on SageMaker from a high level as the diagram above illustrates.
Your notebook (or working environment of your choice) - Used to write the training job definition, and submit it to SageMaker.
SageMaker training job - After your job is submitted, it begins running remotely in Amazon SageMaker on the instance(s) you selected.
Training container - A container image is provided as a parameter to your training job. This container image contains dependencies and anything else needed to run your training code. Once the training job starts, your container is deployed and run.
Training data - Usually, training jobs get training data directly from a specified S3 location.
Model artifacts - When your training job finishes, model artifacts will be packaged and written to S3 as a model.tar.gz file which can be used later to deploy your trained model.
Your notebook or working environment
You can think of SageMaker as two separate components:
- SageMaker Service on AWS – the remote training jobs, deployments, and other infrastructure components that live in AWS
- SageMaker SDK – the SDK used locally to facilitate and encapsulate your SageMaker workflows
As you author your notebook, you’ll utilize the SageMaker SDK to define and manage your training job. It’s worth noting that your training notebook typically doesn’t contain the model and training code itself. Instead, you specify various parameters for your training job, such as the location of your training data, the instance types to be used, and the training container. The actual training code resides either within the designated training container, or is provided as a parameter to your training job.
Like other AWS services, Amazon SageMaker offers various methods of interaction. These include using the console directly, or using tools like the AWS Command Line Interface (CLI), boto3 or any other AWS SDK. However, SageMaker also provides its own SDK.
Unlike other AWS SDKs such as boto3, the SageMaker SDK doesn’t directly mirror the underlying API commands. Instead it was purpose built to work alongside Amazon SageMaker, providing a higher level of abstraction for the more intricate operations taking place within SageMaker.
The SageMaker SDK offers an “Estimator” class which serves as a tool to encapsulate the entire training and deployment workflow on SageMaker. It is commonly used in sample notebooks to facilitate the training process.
A closer look at Estimators
As mentioned above, you can think of an estimator as a python class that will encapsulate your entire model workflow on SageMaker. Let's take a look at a code example below, taken from the AWS documentation. This code sample uses the base estimator class. SageMaker also provides framework specific estimator classes, each works a little differently, but they all extend this base estimator class. Some examples of framework estimators include PyTorch or Tensorflow, we’ll cover these in more detail later.
import sagemaker
region = sagemaker.Session().boto_region_name
print("AWS Region: {}".format(region))
role = sagemaker.get_execution_role()
print("RoleArn: {}".format(role))
s3_output_location=
's3://{}/{}/{}'.format(bucket, prefix,'xgboost_model')
container=sagemaker.image_uris.retrieve("xgboost", region, "1.2-1")
print(container)
xgb_model=sagemaker.estimator.Estimator(
image_uri=container,
role=role,
instance_count=1,
instance_type='ml.m4.xlarge',
volume_size=5,
output_path=s3_output_location,
sagemaker_session=sagemaker.Session()
)
…
from sagemaker.session import TrainingInput
train_input = TrainingInput
("s3://my-bucket/my-prefix/data/train.csv", content_type="csv")
xgb_model.fit({"train": train_input}, wait=True)
(source: https://docs.aws.amazon.com/sagemaker/latest/dg/ex1-train-model.html)
This code sample defines an estimator and then uses it to train a model. Let’s take a look at some of the key parameters used to define the estimator:
- image_uri - this is the container image which runs on the specified instance to carry out training.
- role - IAM role assumed by your training job, used to manage access to other AWS resources.
- instance_type and instance_count - the hardware configurations for your training job.
After the estimator is defined, we use the “fit” method to start training. You also provide your training data information here.
Levels of customization
SageMaker provides several different types of models, each providing a different level of abstraction and customization.
Built-in Algorithms - These models are intended to be used entirely abstracted. No changes are made to the training container, or code. Instead, just set hyperparameters and provide training and validation data. You can read more or see a list of the built-in algorithms SageMaker provides here: Built-in Algorithms — sagemaker 2.159.0 documentation.
Framework Estimators - Framework models provide a container and method for training and deployment. Implementation specifics vary depending on framework, but generally you can provide a training script, without needing to touch the container, or worry about model hosting code when deploying. We will talk more about framework estimators later, but you can see a list of available frameworks here: Frameworks — sagemaker 2.156.0 documentation
Completely Custom - You can also build an entirely custom training strategy by building your own container, or changing an existing one. SageMaker provides a model training toolkit and inference toolkit on GitHub to help you build training and inference containers optimized to run on SageMaker.
Customizing with framework estimators
At Mission Cloud Services, we most commonly see our clients using Framework Estimators when they are migrating existing models to SageMaker, or if they have experience with developing machine learning models. Framework estimators allow you to provide a custom training script, code to pre and post process data, and even specify your python dependencies, while abstracting away other complexities such as code for storing and retrieving data, managing model artifacts, building and registering containers, etc. Some frameworks that are available include Apache MXNet, HuggingFace, PyTorch, Scikit-Learn, TensorFlow, and XGBoost.
Let’s take a look at another code sample. This code sample also uses the XGBoost, but this time using a framework estimator, and custom training script.
from sagemaker.xgboost.estimator import XGBoost
xgb_estimator = XGBoost(
entry_point="abalone.py",
source_dir="./",
hyperparameters=hyperparameters,
role=role,
instance_count=1,
instance_type="ml.m5.2xlarge",
framework_version="1.0-1",
)
…
from sagemaker.inputs import TrainingInput
train_input=TrainingInput(…)
train_input=TrainingInput(…)
xgb_estimator.fit(
{"train”: train_input, "validation": validation_input})
Let’s explore how this estimator definition is different from the one in the previous code example.
- No container URI is provided. Instead, a framework version is specified. The SageMaker SDK will use this information to automatically retrieve the correct container for your training job.
- A script is provided with the entry_point parameter. Here, you can specify a custom script where you can provide your own training code. You can also change the default implementations of input, output, and prediction functions.
- A source directory is also specified using the source_dir parameter. Anything in this directory will be copied into the training job. With most frameworks, if there is a requirements.txt file in the source directory, it will be installed before your training script runs.
To see the full example, or more details on how the XGBoost framework estimator works, you can check out the full notebook example on the Amazon SageMaker Examples GitHub page: Train and deploy a regression model with Amazon SageMaker XGBoost Algorithm using Script Mode
View training jobs and training results in the console
After the training job finishes, the instances are automatically shut down. So what can you see after the training job completes?
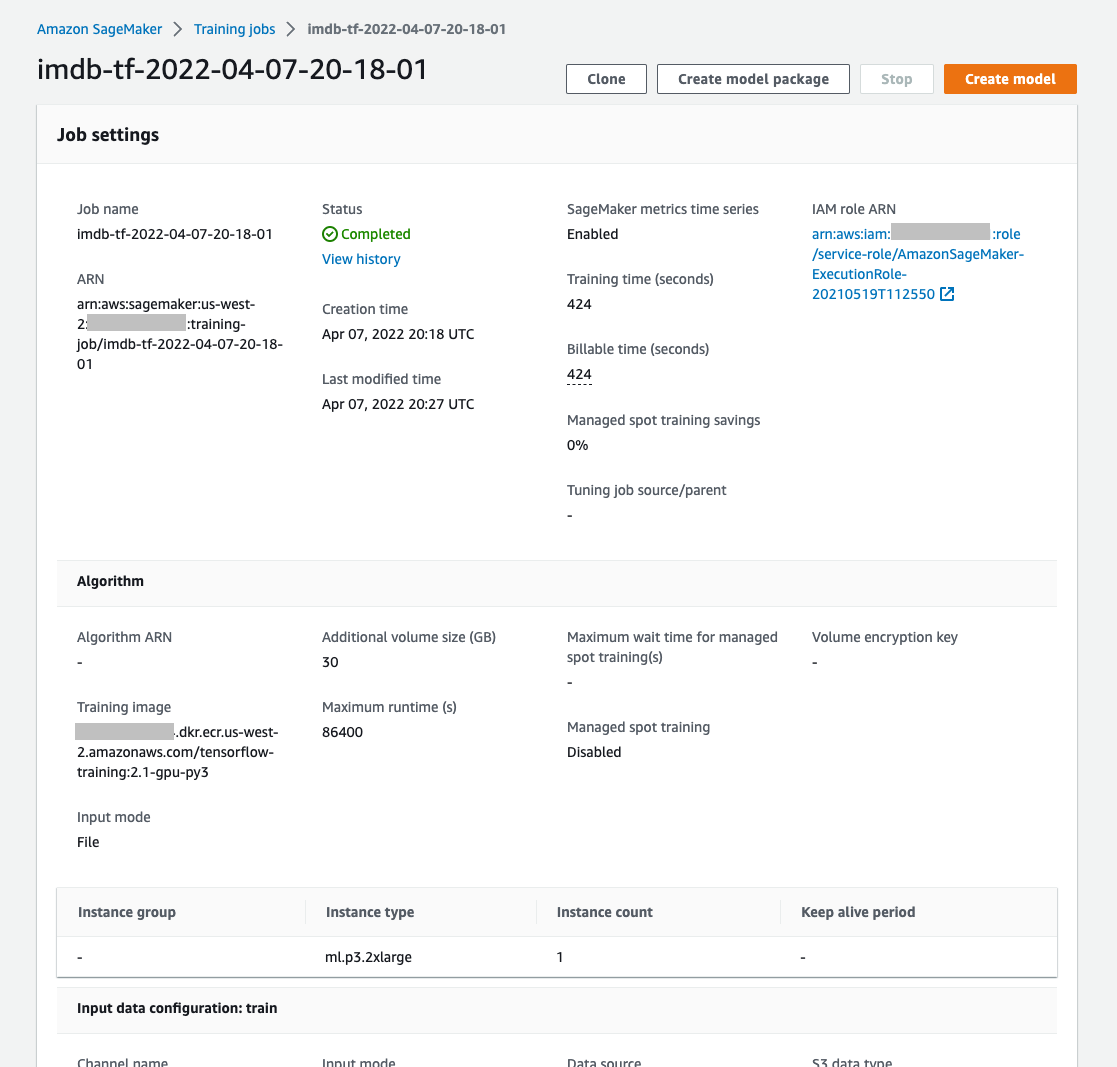
Training job record in the console - SageMaker keeps a record of all past training jobs, which can be seen in the AWS console. You can find a lot of information here including:
- What type of training instance was used, number of instances
- Links to the training job logs, and training instance metrics
- Training container used
- S3 location of the model artifacts resulting from the training job
model.tar.gz file - Before the training job completes, any files which should be persisted are packaged into a model.tar.gz file which is uploaded to S3. Generally this file will include model artifacts such as weights files which can be used to later deploy the trained model. Any other files you wish to persist can also be written to an output path from inside the training job. These files will also be packaged into the resulting model.tar.gz file. Additionally, if you provided a custom model script and/or source files for your training job as part of your estimator definition, they will also be stored in this file.
Performance metrics - many model types have metrics that will automatically be logged to CloudWatch. You can also create custom metrics to be recorded during training to CloudWatch, you can see how it works in our blog post: A Beginner's Guide to Using Custom Metrics in Amazon SageMaker Training Jobs.
Run local code as a SageMaker training job
Amazon SageMaker recently announced a feature that allows you to run your local code as a training job with a single line of code. This can give you some of the benefits of remote training without taking the time to containerize your environment, or refactor your code to work with a SageMaker Estimator. Below is a code sample taken from the AWS Documentation showing how you can easily use this new feature.
from sagemaker.remote_function import remote
@remote(instance_type="ml.m5.4xlarge")
def divide(x, y):
print(f"Calculating {x}/{y}")
return x / y
divide(3, 2)
AWS has provided some other examples and resources for how to run your local code as a SageMaker training job including:
- This GitHub repository with a few example notebooks using the SageMaker remote function
- AWS SageMaker documentation pages on how to run your local code as a SageMaker training job
Conclusion
Now that we've explored the technical details, you're equipped to dive into the world of remote training on SageMaker. So go ahead, unleash your creativity, and start building amazing machine learning models with confidence. The possibilities are endless!
Check out some of Mission’s other blogs about SageMaker here!
- A Beginner's Guide to Using Custom Metrics in Amazon SageMaker Training Jobs
- Amazon SageMaker Studio Tutorial
- What Is SageMaker and How Does It Help MLOps?
- Amazon SageMaker Best Practices
- How to Use Amazon SageMaker Inference Recommender
- Migrate On-Premises Machine Learning Operations to Amazon SageMaker Pipelines for Computer Vision
Links and Additional Resources:
- AWS documentation on SageMaker training: Train Models - Amazon SageMaker
- SageMaker documentation on Training: Using the SageMaker Python SDK -- Train a Model with the SageMaker Python SDK
- AWS Documentation getting started SageMaker notebook example: Get Started with Amazon SageMaker Notebook Instances
- SageMaker documentation about built-in algorithms: Built-in Algorithms — sagemaker 2.159.0 documentation.
- SageMaker documentation about framework algorithms: Frameworks — sagemaker 2.156.0 documentation
- GitHub repository for container toolkits provided by SageMaker:
- SageMaker Examples GitHub repository: GitHub - aws/amazon-sagemaker-examples: Example 📓 Jupyter notebooks that demonstrate how to build, train, and deploy machine learning models using 🧠 Amazon SageMaker.
- SageMaker Examples GitHub – XGBoost example using Script Mode: Train and deploy a regression model with Amazon SageMaker XGBoost Algorithm using Script Mode
- AWS announcement: Amazon SageMaker accelerates local ML code conversion to remote jobs
- GitHub SageMaker remote function examples repository: sagemaker-remote-function
- AWS documentation for SageMaker Remote Decorator – Run your local code as a SageMaker training job
FAQ
- What are the limitations or challenges associated with using SageMaker for remote training compared to local machine-learning setups?
The limitations or challenges associated with using Amazon SageMaker for remote training include the potential complexity of setting up and optimizing the environment, dependency on internet connectivity, and, sometimes, latency issues compared to local setups. These challenges require careful management of resources and configuration to optimize the machine learning pipeline and ensure efficient operation.
- How can organizations ensure data security when using SageMaker for remote training, especially when dealing with sensitive or proprietary data?
To ensure data security when using SageMaker for remote training, organizations should utilize AWS’s built-in security measures, such as data encryption at rest and in transit, manage access permissions meticulously using IAM roles, and employ VPCs to isolate training data. These practices help safeguard sensitive or proprietary information throughout the machine-learning process.
- What are the cost implications of switching from local training setups to SageMaker's remote training capabilities?
- Switching from local training setups to SageMaker's remote training capabilities can lead to various cost implications. While SageMaker may increase operational efficiency and reduce the need for on-premises hardware, the costs of cloud computing resources and data transfer must be considered. SageMaker provides cost management tools to track expenses and optimize resource allocation, helping balance performance with budget constraints.



